- Introduction
- Philosophical overview
- Design goals
- Comparison to Make
- Using Ninja for your project
- Running Ninja
- Environment variables
- Extra tools
- Writing your own Ninja files
- Conceptual overview
- Syntax example
- Variables
- Rules
- Build statements
- Generating Ninja files from code
- More details
- The
phonyrule - Default target statements
- The Ninja log
- Version compatibility
- C/C++ header dependencies
- depfile
- deps
- Pools
- The
consolepool
- The
- The
- Ninja file reference
- Lexical syntax
- Top-level variables
- Rule variables
- Interpretation of the
commandvariable
- Interpretation of the
- Build outputs
- Build dependencies
- Validations
- Variable expansion
- Evaluation and scoping
- Dynamic Dependencies
- Dyndep file reference
- Dyndep Examples
- Fortran Modules
- Tarball Extraction
Introduction
Ninja is yet another build system. It takes as input the
interdependencies of files (typically source code and output
executables) and orchestrates building them, quickly.
Ninja joins a sea of other build systems. Its distinguishing goal is
to be fast. It is born from
my
work on the Chromium browser project, which has over 30,000 source
files and whose other build systems (including one built from custom
non-recursive Makefiles) would take ten seconds to start building
after changing one file. Ninja is under a second.
Philosophical overview
Where other build systems are high-level languages, Ninja aims to be
an assembler.
Build systems get slow when they need to make decisions. When you are
in a edit-compile cycle you want it to be as fast as possible — you
want the build system to do the minimum work necessary to figure out
what needs to be built immediately.
Ninja contains the barest functionality necessary to describe
arbitrary dependency graphs. Its lack of syntax makes it impossible
to express complex decisions.
Instead, Ninja is intended to be used with a separate program
generating its input files. The generator program (like the
./configure found in autotools projects) can analyze system
dependencies and make as many decisions as possible up front so that
incremental builds stay fast. Going beyond autotools, even build-time
decisions like «which compiler flags should I use?» or «should I
build a debug or release-mode binary?» belong in the .ninja file
generator.
Design goals
Here are the design goals of Ninja:
-
very fast (i.e., instant) incremental builds, even for very large
projects. -
very little policy about how code is built. Different projects and
higher-level build systems have different opinions about how code
should be built; for example, should built objects live alongside
the sources or should all build output go into a separate directory?
Is there a «package» rule that builds a distributable package of
the project? Sidestep these decisions by trying to allow either to
be implemented, rather than choosing, even if that results in
more verbosity. -
get dependencies correct, and in particular situations that are
difficult to get right with Makefiles (e.g. outputs need an implicit
dependency on the command line used to generate them; to build C
source code you need to use gcc’s-Mflags for header
dependencies). - when convenience and speed are in conflict, prefer speed.
Some explicit non-goals:
-
convenient syntax for writing build files by hand. You should
generate your ninja files using another program. This is how we
can sidestep many policy decisions. -
built-in rules. Out of the box, Ninja has no rules for
e.g. compiling C code. -
build-time customization of the build. Options belong in
the program that generates the ninja files. -
build-time decision-making ability such as conditionals or search
paths. Making decisions is slow.
To restate, Ninja is faster than other build systems because it is
painfully simple. You must tell Ninja exactly what to do when you
create your project’s .ninja files.
Comparison to Make
Ninja is closest in spirit and functionality to Make, relying on
simple dependencies between file timestamps.
But fundamentally, make has a lot of features: suffix rules,
functions, built-in rules that e.g. search for RCS files when building
source. Make’s language was designed to be written by humans. Many
projects find make alone adequate for their build problems.
In contrast, Ninja has almost no features; just those necessary to get
builds correct while punting most complexity to generation of the
ninja input files. Ninja by itself is unlikely to be useful for most
projects.
Here are some of the features Ninja adds to Make. (These sorts of
features can often be implemented using more complicated Makefiles,
but they are not part of make itself.)
-
Ninja has special support for discovering extra dependencies at build
time, making it easy to get header dependencies
correct for C/C++ code. - A build edge may have multiple outputs.
-
Outputs implicitly depend on the command line that was used to generate
them, which means that changing e.g. compilation flags will cause
the outputs to rebuild. -
Output directories are always implicitly created before running the
command that relies on them. -
Rules can provide shorter descriptions of the command being run, so
you can print e.g.CC foo.oinstead of a long command line while
building. -
Builds are always run in parallel, based by default on the number of
CPUs your system has. Underspecified build dependencies will result
in incorrect builds. -
Command output is always buffered. This means commands running in
parallel don’t interleave their output, and when a command fails we
can print its failure output next to the full command line that
produced the failure.
Using Ninja for your project
Ninja currently works on Unix-like systems and Windows. It’s seen the
most testing on Linux (and has the best performance there) but it runs
fine on Mac OS X and FreeBSD.
If your project is small, Ninja’s speed impact is likely unnoticeable.
(However, even for small projects it sometimes turns out that Ninja’s
limited syntax forces simpler build rules that result in faster
builds.) Another way to say this is that if you’re happy with the
edit-compile cycle time of your project already then Ninja won’t help.
There are many other build systems that are more user-friendly or
featureful than Ninja itself. For some recommendations: the Ninja
author found the tup build system influential
in Ninja’s design, and thinks redo’s
design is quite clever.
Ninja’s benefit comes from using it in conjunction with a smarter
meta-build system.
gn
-
The meta-build system used to
generate build files for Google Chrome and related projects (v8,
node.js), as well as Google Fuchsia. gn can generate Ninja files for
all platforms supported by Chrome.
CMake
-
A widely used meta-build system that
can generate Ninja files on Linux as of CMake version 2.8.8. Newer versions
of CMake support generating Ninja files on Windows and Mac OS X too.
others
-
Ninja ought to fit perfectly into other meta-build software
like premake. If you do this work,
please let us know!
Running Ninja
Run ninja. By default, it looks for a file named build.ninja in
the current directory and builds all out-of-date targets. You can
specify which targets (files) to build as command line arguments.
There is also a special syntax target^ for specifying a target
as the first output of some rule containing the source you put in
the command line, if one exists. For example, if you specify target as
foo.c^ then foo.o will get built (assuming you have those targets
in your build files).
ninja -h prints help output. Many of Ninja’s flags intentionally
match those of Make; e.g ninja -C build -j 20 changes into the
build directory and runs 20 build commands in parallel. (Note that
Ninja defaults to running commands in parallel anyway, so typically
you don’t need to pass -j.)
Environment variables
Ninja supports one environment variable to control its behavior:
NINJA_STATUS, the progress status printed before the rule being run.
Several placeholders are available:
%s
- The number of started edges.
%t
- The total number of edges that must be run to complete the build.
%p
- The percentage of started edges.
%r
- The number of currently running edges.
%u
- The number of remaining edges to start.
%f
- The number of finished edges.
%o
- Overall rate of finished edges per second
%c
-
Current rate of finished edges per second (average over builds
specified by-jor its default)
%e
- Elapsed time in seconds. (Available since Ninja 1.2.)
%%
-
A plain
%character.
The default progress status is "[%f/%t] " (note the trailing space
to separate from the build rule). Another example of possible progress status
could be "[%u/%r/%f] ".
Extra tools
The -t flag on the Ninja command line runs some tools that we have
found useful during Ninja’s development. The current tools are:
|
|
dump the inputs and outputs of a given target. |
|
|
browse the dependency graph in a web browser. Clicking a ninja -t browse --port=8000 --no-browser mytarget |
|
|
output a file in the syntax used by ninja -t graph mytarget | dot -Tpng -ograph.png In the Ninja source tree, |
|
|
output a list of targets either by rule or by depth. If used |
|
|
given a list of targets, print a list of commands which, if |
|
|
given a list of targets, print a list of all inputs used to |
|
|
remove built files. By default it removes all built files If used like Files created but not referenced in the graph are not removed. This |
|
|
remove files produced by previous builds that are no longer in the |
|
|
given a list of rules, each of which is expected to be a |
|
|
show all dependencies stored in the |
|
|
given a list of targets, look for targets that depend on The broken targets can be found assuming deps log / depfile dependency The tool’s findings can be verified by trying to build the listed targets in |
|
|
recompact the |
|
|
updates all recorded file modification timestamps in the |
|
|
output the list of all rules. It can be used to know which rule name |
|
|
Available on Windows hosts only. ninja -t msvc -e ENVFILE -- cl.exe <arguments> Where |
This tool also supports a deprecated way of parsing the compiler’s output when
the /showIncludes flag is used, and generating a GCC-compatible depfile from it.
+
—
ninja -t msvc -o DEPFILE [-p STRING] — cl.exe /showIncludes <arguments>
—
+
When using this option, -p STRING can be used to pass the localized line prefix
that cl.exe uses to output dependency information. For English-speaking regions
this is "Note: including file: " without the double quotes, but will be different
for other regions.
Note that Ninja supports this natively now, with the use of deps = msvc and
msvc_deps_prefix in Ninja files. Native support also avoids launching an extra
tool process each time the compiler must be called, which can speed up builds
noticeably on Windows.
wincodepage
-
Available on Windows hosts (since Ninja 1.11).
Prints the Windows code page whose encoding is expected in the build file.
The output has the form:Build file encoding: <codepage>
Additional lines may be added in future versions of Ninja.
The
<codepage>is one of:
UTF-8
- Encode as UTF-8.
ANSI
- Encode to the system-wide ANSI code page.
Writing your own Ninja files
The remainder of this manual is only useful if you are constructing
Ninja files yourself: for example, if you’re writing a meta-build
system or supporting a new language.
Conceptual overview
Ninja evaluates a graph of dependencies between files, and runs
whichever commands are necessary to make your build target up to date
as determined by file modification times. If you are familiar with
Make, Ninja is very similar.
A build file (default name: build.ninja) provides a list of rules — short names for longer commands, like how to run the compiler — along with a list of build statements saying how to build files
using the rules — which rule to apply to which inputs to produce
which outputs.
Conceptually, build statements describe the dependency graph of your
project, while rule statements describe how to generate the files
along a given edge of the graph.
Syntax example
Here’s a basic .ninja file that demonstrates most of the syntax.
It will be used as an example for the following sections.
cflags = -Wall rule cc command = gcc $cflags -c $in -o $out build foo.o: cc foo.c
Variables
Despite the non-goal of being convenient to write by hand, to keep
build files readable (debuggable), Ninja supports declaring shorter
reusable names for strings. A declaration like the following
cflags = -g
can be used on the right side of an equals sign, dereferencing it with
a dollar sign, like this:
rule cc command = gcc $cflags -c $in -o $out
Variables can also be referenced using curly braces like ${in}.
Variables might better be called «bindings», in that a given variable
cannot be changed, only shadowed. There is more on how shadowing works
later in this document.
Rules
Rules declare a short name for a command line. They begin with a line
consisting of the rule keyword and a name for the rule. Then
follows an indented set of variable = value lines.
The basic example above declares a new rule named cc, along with the
command to run. In the context of a rule, the command variable
defines the command to run, $in expands to the list of
input files (foo.c), and $out to the output files (foo.o) for the
command. A full list of special variables is provided in
the reference.
Build statements
Build statements declare a relationship between input and output
files. They begin with the build keyword, and have the format
build outputs: rulename inputs. Such a declaration says that
all of the output files are derived from the input files. When the
output files are missing or when the inputs change, Ninja will run the
rule to regenerate the outputs.
The basic example above describes how to build foo.o, using the cc
rule.
In the scope of a build block (including in the evaluation of its
associated rule), the variable $in is the list of inputs and the
variable $out is the list of outputs.
A build statement may be followed by an indented set of key = value
pairs, much like a rule. These variables will shadow any variables
when evaluating the variables in the command. For example:
cflags = -Wall -Werror rule cc command = gcc $cflags -c $in -o $out # If left unspecified, builds get the outer $cflags. build foo.o: cc foo.c # But you can shadow variables like cflags for a particular build. build special.o: cc special.c cflags = -Wall # The variable was only shadowed for the scope of special.o; # Subsequent build lines get the outer (original) cflags. build bar.o: cc bar.c
For more discussion of how scoping works, consult the reference.
If you need more complicated information passed from the build
statement to the rule (for example, if the rule needs «the file
extension of the first input»), pass that through as an extra
variable, like how cflags is passed above.
If the top-level Ninja file is specified as an output of any build
statement and it is out of date, Ninja will rebuild and reload it
before building the targets requested by the user.
Generating Ninja files from code
misc/ninja_syntax.py in the Ninja distribution is a tiny Python
module to facilitate generating Ninja files. It allows you to make
Python calls like ninja.rule(name='foo', command='bar', and it will generate the appropriate syntax. Feel
depfile='$out.d')
free to just inline it into your project’s build system if it’s
useful.
More details
The phony rule
The special rule name phony can be used to create aliases for other
targets. For example:
build foo: phony some/file/in/a/faraway/subdir/foo
This makes ninja foo build the longer path. Semantically, the
phony rule is equivalent to a plain rule where the command does
nothing, but phony rules are handled specially in that they aren’t
printed when run, logged (see below), nor do they contribute to the
command count printed as part of the build process.
When a phony target is used as an input to another build rule, the
other build rule will, semantically, consider the inputs of the
phony rule as its own. Therefore, phony rules can be used to group
inputs, e.g. header files.
phony can also be used to create dummy targets for files which
may not exist at build time. If a phony build statement is written
without any dependencies, the target will be considered out of date if
it does not exist. Without a phony build statement, Ninja will report
an error if the file does not exist and is required by the build.
To create a rule that never rebuilds, use a build rule without any input:
rule touch command = touch $out build file_that_always_exists.dummy: touch build dummy_target_to_follow_a_pattern: phony file_that_always_exists.dummy
Default target statements
By default, if no targets are specified on the command line, Ninja
will build every output that is not named as an input elsewhere.
You can override this behavior using a default target statement.
A default target statement causes Ninja to build only a given subset
of output files if none are specified on the command line.
Default target statements begin with the default keyword, and have
the format default targets. A default target statement must appear
after the build statement that declares the target as an output file.
They are cumulative, so multiple statements may be used to extend
the list of default targets. For example:
default foo bar default baz
This causes Ninja to build the foo, bar and baz targets by
default.
The Ninja log
For each built file, Ninja keeps a log of the command used to build
it. Using this log Ninja can know when an existing output was built
with a different command line than the build files specify (i.e., the
command line changed) and knows to rebuild the file.
The log file is kept in the build root in a file called .ninja_log.
If you provide a variable named builddir in the outermost scope,
.ninja_log will be kept in that directory instead.
Version compatibility
Available since Ninja 1.2.
Ninja version labels follow the standard major.minor.patch format,
where the major version is increased on backwards-incompatible
syntax/behavioral changes and the minor version is increased on new
behaviors. Your build.ninja may declare a variable named
ninja_required_version that asserts the minimum Ninja version
required to use the generated file. For example,
ninja_required_version = 1.1
declares that the build file relies on some feature that was
introduced in Ninja 1.1 (perhaps the pool syntax), and that
Ninja 1.1 or greater must be used to build. Unlike other Ninja
variables, this version requirement is checked immediately when
the variable is encountered in parsing, so it’s best to put it
at the top of the build file.
Ninja always warns if the major versions of Ninja and the
ninja_required_version don’t match; a major version change hasn’t
come up yet so it’s difficult to predict what behavior might be
required.
C/C++ header dependencies
To get C/C++ header dependencies (or any other build dependency that
works in a similar way) correct Ninja has some extra functionality.
The problem with headers is that the full list of files that a given
source file depends on can only be discovered by the compiler:
different preprocessor defines and include paths cause different files
to be used. Some compilers can emit this information while building,
and Ninja can use that to get its dependencies perfect.
Consider: if the file has never been compiled, it must be built anyway,
generating the header dependencies as a side effect. If any file is
later modified (even in a way that changes which headers it depends
on) the modification will cause a rebuild as well, keeping the
dependencies up to date.
When loading these special dependencies, Ninja implicitly adds extra
build edges such that it is not an error if the listed dependency is
missing. This allows you to delete a header file and rebuild without
the build aborting due to a missing input.
depfile
gcc (and other compilers like clang) support emitting dependency
information in the syntax of a Makefile. (Any command that can write
dependencies in this form can be used, not just gcc.)
To bring this information into Ninja requires cooperation. On the
Ninja side, the depfile attribute on the build must point to a
path where this data is written. (Ninja only supports the limited
subset of the Makefile syntax emitted by compilers.) Then the command
must know to write dependencies into the depfile path.
Use it like in the following example:
rule cc depfile = $out.d command = gcc -MD -MF $out.d [other gcc flags here]
The -MD flag to gcc tells it to output header dependencies, and
the -MF flag tells it where to write them.
deps
(Available since Ninja 1.3.)
It turns out that for large projects (and particularly on Windows,
where the file system is slow) loading these dependency files on
startup is slow.
Ninja 1.3 can instead process dependencies just after they’re generated
and save a compacted form of the same information in a Ninja-internal
database.
Ninja supports this processing in two forms.
-
deps = gccspecifies that the tool outputsgcc-style dependencies
in the form of Makefiles. Adding this to the above example will
cause Ninja to process thedepfileimmediately after the
compilation finishes, then delete the.dfile (which is only used
as a temporary). -
deps = msvcspecifies that the tool outputs header dependencies
in the form produced by Visual Studio’s compiler’s
/showIncludes
flag. Briefly, this means the tool outputs specially-formatted lines
to its stdout. Ninja then filters these lines from the displayed
output. Nodepfileattribute is necessary, but the localized string
in front of the the header file path. For instance
msvc_deps_prefix = Note: including file:
for a English Visual Studio (the default). Should be globally defined.msvc_deps_prefix = Note: including file: rule cc deps = msvc command = cl /showIncludes -c $in /Fo$out
If the include directory directives are using absolute paths, your depfile
may result in a mixture of relative and absolute paths. Paths used by other
build rules need to match exactly. Therefore, it is recommended to use
relative paths in these cases.
Pools
Available since Ninja 1.1.
Pools allow you to allocate one or more rules or edges a finite number
of concurrent jobs which is more tightly restricted than the default
parallelism.
This can be useful, for example, to restrict a particular expensive rule
(like link steps for huge executables), or to restrict particular build
statements which you know perform poorly when run concurrently.
Each pool has a depth variable which is specified in the build file.
The pool is then referred to with the pool variable on either a rule
or a build statement.
No matter what pools you specify, ninja will never run more concurrent jobs
than the default parallelism, or the number of jobs specified on the command
line (with -j).
# No more than 4 links at a time. pool link_pool depth = 4 # No more than 1 heavy object at a time. pool heavy_object_pool depth = 1 rule link ... pool = link_pool rule cc ... # The link_pool is used here. Only 4 links will run concurrently. build foo.exe: link input.obj # A build statement can be exempted from its rule's pool by setting an # empty pool. This effectively puts the build statement back into the default # pool, which has infinite depth. build other.exe: link input.obj pool = # A build statement can specify a pool directly. # Only one of these builds will run at a time. build heavy_object1.obj: cc heavy_obj1.cc pool = heavy_object_pool build heavy_object2.obj: cc heavy_obj2.cc pool = heavy_object_pool
The console pool
Available since Ninja 1.5.
There exists a pre-defined pool named console with a depth of 1. It has
the special property that any task in the pool has direct access to the
standard input, output and error streams provided to Ninja, which are
normally connected to the user’s console (hence the name) but could be
redirected. This can be useful for interactive tasks or long-running tasks
which produce status updates on the console (such as test suites).
While a task in the console pool is running, Ninja’s regular output (such
as progress status and output from concurrent tasks) is buffered until
it completes.
Ninja file reference
A file is a series of declarations. A declaration can be one of:
-
A rule declaration, which begins with
rule rulename, and
then has a series of indented lines defining variables. -
A build edge, which looks like
build output1 output2:.
rulename input1 input2
Implicit dependencies may be tacked on the end with|.
dependency1 dependency2
Order-only dependencies may be tacked on the end with||. (See the reference on dependency types.)
dependency1 dependency2
Validations may be taked on the end with|@ validation1 validation2.
(See the reference on validations.)Implicit outputs (available since Ninja 1.7) may be added before
the:with| output1 output2and do not appear in$out.
(See the reference on output types.) -
Variable declarations, which look like
variable = value. -
Default target statements, which look like
default target1 target2. -
References to more files, which look like
subninja pathor
include path. The difference between these is explained below
in the discussion about scoping. -
A pool declaration, which looks like
pool poolname. Pools are explained
in the section on pools.
Lexical syntax
Ninja is mostly encoding agnostic, as long as the bytes Ninja cares
about (like slashes in paths) are ASCII. This means e.g. UTF-8 or
ISO-8859-1 input files ought to work.
Comments begin with # and extend to the end of the line.
Newlines are significant. Statements like build foo bar are a set
of space-separated tokens that end at the newline. Newlines and
spaces within a token must be escaped.
There is only one escape character, $, and it has the following
behaviors:
$followed by a newline
-
escape the newline (continue the current line
across a line break).
$followed by text
- a variable reference.
${varname}
-
alternate syntax for
$varname.
$followed by space
-
a space. (This is only necessary in lists of
paths, where a space would otherwise separate filenames. See below.)
$:
-
a colon. (This is only necessary in
buildlines, where a colon
would otherwise terminate the list of outputs.)
$$
-
a literal
$.
A build or default statement is first parsed as a space-separated
list of filenames and then each name is expanded. This means that
spaces within a variable will result in spaces in the expanded
filename.
spaced = foo bar build $spaced/baz other$ file: ... # The above build line has two outputs: "foo bar/baz" and "other file".
In a name = value statement, whitespace at the beginning of a value
is always stripped. Whitespace at the beginning of a line after a
line continuation is also stripped.
two_words_with_one_space = foo $
bar
one_word_with_no_space = foo$
bar
Other whitespace is only significant if it’s at the beginning of a
line. If a line is indented more than the previous one, it’s
considered part of its parent’s scope; if it is indented less than the
previous one, it closes the previous scope.
Top-level variables
Two variables are significant when declared in the outermost file scope.
builddir
-
a directory for some Ninja output files. See the discussion of the build log. (You can also store other build output
in this directory.)
ninja_required_version
-
the minimum version of Ninja required to process
the build correctly. See the discussion of versioning.
Rule variables
A rule block contains a list of key = value declarations that
affect the processing of the rule. Here is a full list of special
keys.
command(required)
-
the command line to run. Each
rulemay
have only onecommanddeclaration. See the next section for more details on quoting and executing multiple commands.
depfile
-
path to an optional
Makefilethat contains extra
implicit dependencies (see the reference on dependency types). This is explicitly to support C/C++ header
dependencies; see the full discussion.
deps
-
(Available since Ninja 1.3.) if present, must be one of
gccormsvcto specify special dependency processing. See
the full discussion. The generated database is
stored as.ninja_depsin thebuilddir, see the discussion ofbuilddir.
msvc_deps_prefix
-
(Available since Ninja 1.5.) defines the string
which should be stripped from msvc’s /showIncludes output. Only
needed whendeps = msvcand no English Visual Studio version is used.
description
-
a short description of the command, used to pretty-print
the command as it’s running. The-vflag controls whether to print
the full command or its description; if a command fails, the full command
line will always be printed before the command’s output.
dyndep
-
(Available since Ninja 1.10.) Used only on build statements.
If present, must name one of the build statement inputs. Dynamically
discovered dependency information will be loaded from the file.
See the dynamic dependencies section for details.
generator
-
if present, specifies that this rule is used to
re-invoke the generator program. Files built usinggenerator
rules are treated specially in two ways: firstly, they will not be
rebuilt if the command line changes; and secondly, they are not
cleaned by default.
in
-
the space-separated list of files provided as inputs to the build line
referencing thisrule, shell-quoted if it appears in commands. ($inis
provided solely for convenience; if you need some subset or variant of this
list of files, just construct a new variable with that list and use
that instead.)
in_newline
-
the same as
$inexcept that multiple inputs are
separated by newlines rather than spaces. (For use with
$rspfile_content; this works around a bug in the MSVC linker where
it uses a fixed-size buffer for processing input.)
out
-
the space-separated list of files provided as outputs to the build line
referencing thisrule, shell-quoted if it appears in commands.
restat
-
if present, causes Ninja to re-stat the command’s outputs
after execution of the command. Each output whose modification time
the command did not change will be treated as though it had never
needed to be built. This may cause the output’s reverse
dependencies to be removed from the list of pending build actions.
rspfile,rspfile_content
-
if present (both), Ninja will use a
response file for the given command, i.e. write the selected string
(rspfile_content) to the given file (rspfile) before calling the
command and delete the file after successful execution of the
command.This is particularly useful on Windows OS, where the maximal length of
a command line is limited and response files must be used instead.Use it like in the following example:
rule link command = link.exe /OUT$out [usual link flags here] @$out.rsp rspfile = $out.rsp rspfile_content = $in build myapp.exe: link a.obj b.obj [possibly many other .obj files]
Interpretation of the command variable
Fundamentally, command lines behave differently on Unixes and Windows.
On Unixes, commands are arrays of arguments. The Ninja command
variable is passed directly to sh -c, which is then responsible for
interpreting that string into an argv array. Therefore the quoting
rules are those of the shell, and you can use all the normal shell
operators, like && to chain multiple commands, or VAR=value cmd to
set environment variables.
On Windows, commands are strings, so Ninja passes the command string
directly to CreateProcess. (In the common case of simply executing
a compiler this means there is less overhead.) Consequently the
quoting rules are determined by the called program, which on Windows
are usually provided by the C library. If you need shell
interpretation of the command (such as the use of && to chain
multiple commands), make the command execute the Windows shell by
prefixing the command with cmd /c. Ninja may error with «invalid parameter»
which usually indicates that the command line length has been exceeded.
Build outputs
There are two types of build outputs which are subtly different.
-
Explicit outputs, as listed in a build line. These are
available as the$outvariable in the rule.This is the standard form of output to be used for e.g. the
object file of a compile command. -
Implicit outputs, as listed in a build line with the syntax
|+ before the
out1 out2:of a build line (available since
Ninja 1.7). The semantics are identical to explicit outputs,
the only difference is that implicit outputs don’t show up in the
$outvariable.This is for expressing outputs that don’t show up on the
command line of the command.
Build dependencies
There are three types of build dependencies which are subtly different.
-
Explicit dependencies, as listed in a build line. These are
available as the$invariable in the rule. Changes in these files
cause the output to be rebuilt; if these files are missing and
Ninja doesn’t know how to build them, the build is aborted.This is the standard form of dependency to be used e.g. for the
source file of a compile command. -
Implicit dependencies, either as picked up from
adepfileattribute on a rule or from the syntax| dep1on the end of a build line. The semantics are identical to
dep2
explicit dependencies, the only difference is that implicit dependencies
don’t show up in the$invariable.This is for expressing dependencies that don’t show up on the
command line of the command; for example, for a rule that runs a
script that reads a hardcoded file, the hardcoded file should
be an implicit dependency, as changes to the file should cause
the output to rebuild, even though it doesn’t show up in the arguments.Note that dependencies as loaded through depfiles have slightly different
semantics, as described in the rule reference. -
Order-only dependencies, expressed with the syntax
|| dep1on the end of a build line. When these are out of date, the
dep2
output is not rebuilt until they are built, but changes in order-only
dependencies alone do not cause the output to be rebuilt.Order-only dependencies can be useful for bootstrapping dependencies
that are only discovered during build time: for example, to generate a
header file before starting a subsequent compilation step. (Once the
header is used in compilation, a generated dependency file will then
express the implicit dependency.)
File paths are compared as is, which means that an absolute path and a
relative path, pointing to the same file, are considered different by Ninja.
Validations
Validations listed on the build line cause the specified files to be
added to the top level of the build graph (as if they were specified
on the Ninja command line) whenever the build line is a transitive
dependency of one of the targets specified on the command line or a
default target.
Validations are added to the build graph regardless of whether the output
files of the build statement are dirty are not, and the dirty state of
the build statement that outputs the file being used as a validation
has no effect on the dirty state of the build statement that requested it.
A build edge can list another build edge as a validation even if the second
edge depends on the first.
Validations are designed to handle rules that perform error checking but
don’t produce any artifacts needed by the build, for example static
analysis tools. Marking the static analysis rule as an implicit input
of the main build rule of the source files or of the rules that depend
on the main build rule would slow down the critical path of the build,
but using a validation would allow the build to proceed in parallel with
the static analysis rule once the main build rule is complete.
Variable expansion
Variables are expanded in paths (in a build or default statement)
and on the right side of a name = value statement.
When a name = value statement is evaluated, its right-hand side is
expanded immediately (according to the below scoping rules), and
from then on $name expands to the static string as the result of the
expansion. It is never the case that you’ll need to «double-escape» a
value to prevent it from getting expanded twice.
All variables are expanded immediately as they’re encountered in parsing,
with one important exception: variables in rule blocks are expanded
when the rule is used, not when it is declared. In the following
example, the demo rule prints «this is a demo of bar».
rule demo command = echo "this is a demo of $foo" build out: demo foo = bar
Evaluation and scoping
Top-level variable declarations are scoped to the file they occur in.
Rule declarations are also scoped to the file they occur in.
(Available since Ninja 1.6)
The subninja keyword, used to include another .ninja file,
introduces a new scope. The included subninja file may use the
variables and rules from the parent file, and shadow their values for the file’s
scope, but it won’t affect values of the variables in the parent.
To include another .ninja file in the current scope, much like a C
#include statement, use include instead of subninja.
Variable declarations indented in a build block are scoped to the
build block. The full lookup order for a variable expanded in a
build block (or the rule is uses) is:
-
Special built-in variables (
$in,$out). -
Build-level variables from the
buildblock. -
Rule-level variables from the
ruleblock (i.e.$command).
(Note from the above discussion on expansion that these are
expanded «late», and may make use of in-scope bindings like$in.) -
File-level variables from the file that the
buildline was in. -
Variables from the file that included that file using the
subninjakeyword.
Dynamic Dependencies
Available since Ninja 1.10.
Some use cases require implicit dependency information to be dynamically
discovered from source file content during the build in order to build
correctly on the first run (e.g. Fortran module dependencies). This is
unlike header dependencies which are only needed on the
second run and later to rebuild correctly. A build statement may have a
dyndep binding naming one of its inputs to specify that dynamic
dependency information must be loaded from the file. For example:
build out: ... || foo dyndep = foo build foo: ...
This specifies that file foo is a dyndep file. Since it is an input,
the build statement for out can never be executed before foo is built.
As soon as foo is finished Ninja will read it to load dynamically
discovered dependency information for out. This may include additional
implicit inputs and/or outputs. Ninja will update the build graph
accordingly and the build will proceed as if the information was known
originally.
Dyndep file reference
Files specified by dyndep bindings use the same lexical syntax
as ninja build files and have the following layout.
-
A version number in the form
<major>[.<minor>][<suffix>]:ninja_dyndep_version = 1
Currently the version number must always be
1or1.0but may have
an arbitrary suffix. -
One or more build statements of the form:
build out | imp-outs... : dyndep | imp-ins...
Every statement must specify exactly one explicit output and must use
the rule namedyndep. The| imp-outs...and| imp-ins...portions
are optional. -
An optional
restatvariable binding on each build statement.
The build statements in a dyndep file must have a one-to-one correspondence
to build statements in the ninja build file that name the
dyndep file in a dyndep binding. No dyndep build statement may be omitted
and no extra build statements may be specified.
Dyndep Examples
Fortran Modules
Consider a Fortran source file foo.f90 that provides a module
foo.mod (an implicit output of compilation) and another source file
bar.f90 that uses the module (an implicit input of compilation). This
implicit dependency must be discovered before we compile either source
in order to ensure that bar.f90 never compiles before foo.f90, and
that bar.f90 recompiles when foo.mod changes. We can achieve this
as follows:
rule f95 command = f95 -o $out -c $in rule fscan command = fscan -o $out $in build foobar.dd: fscan foo.f90 bar.f90 build foo.o: f95 foo.f90 || foobar.dd dyndep = foobar.dd build bar.o: f95 bar.f90 || foobar.dd dyndep = foobar.dd
In this example the order-only dependencies ensure that foobar.dd is
generated before either source compiles. The hypothetical fscan tool
scans the source files, assumes each will be compiled to a .o of the
same name, and writes foobar.dd with content such as:
ninja_dyndep_version = 1 build foo.o | foo.mod: dyndep build bar.o: dyndep | foo.mod
Ninja will load this file to add foo.mod as an implicit output of
foo.o and implicit input of bar.o. This ensures that the Fortran
sources are always compiled in the proper order and recompiled when
needed.
Tarball Extraction
Consider a tarball foo.tar that we want to extract. The extraction time
can be recorded with a foo.tar.stamp file so that extraction repeats if
the tarball changes, but we also would like to re-extract if any of the
outputs is missing. However, the list of outputs depends on the content
of the tarball and cannot be spelled out explicitly in the ninja build file.
We can achieve this as follows:
rule untar command = tar xf $in && touch $out rule scantar command = scantar --stamp=$stamp --dd=$out $in build foo.tar.dd: scantar foo.tar stamp = foo.tar.stamp build foo.tar.stamp: untar foo.tar || foo.tar.dd dyndep = foo.tar.dd
In this example the order-only dependency ensures that foo.tar.dd is
built before the tarball extracts. The hypothetical scantar tool
will read the tarball (e.g. via tar tf) and write foo.tar.dd with
content such as:
ninja_dyndep_version = 1 build foo.tar.stamp | file1.txt file2.txt : dyndep restat = 1
Ninja will load this file to add file1.txt and file2.txt as implicit
outputs of foo.tar.stamp, and to mark the build statement for restat.
On future builds, if any implicit output is missing the tarball will be
extracted again. The restat binding tells Ninja to tolerate the fact
that the implicit outputs may not have modification times newer than
the tarball itself (avoiding re-extraction on every build).
We’re Earthly. We simplify and speed up software building using containerization. It’s a different approach then you’ll find in Ninja and you may want to check it out.
Ninja is a compact build system with a focus on fast incremental builds. It was originally developed by Evan Martin, a Google dev, partly in response to the needs of building large projects such as Google Chrome.
If you’re developing a software system and you require a rebuild every few minutes to test your latest feature or code block, then Ninja will only rebuild what you have just modified or added and nothing else—as opposed to Make, which would rebuild the whole project every single time.
This article will start by explaining build systems in a little more detail. It’ll then introduce Ninja and teach you how to use Ninja to build a simple C++ project.
What Is a Build System?
Software projects are usually composed of many files. And the process of compiling, linking, copying, structuring, testing, or more generally, processing these files into an executable program is called a build.
Build systems fall into two broad categories:
- Build generator: Software that takes as input a spec file written in a specially designed language (in many cases, Turing Complete programming languages) and generates a build file that tells build tools how to go about building a software package.
- Build tool: Software that takes in a build file previously generated by a build generator and then builds a software package. Ninja is an example of a build tool.
Next, let’s take a closer look at Ninja and when you may want to use it.
What Is Ninja?

Ninja is a fast build tool that can also be used as a build tool for other build generators. As mentioned, it was originally developed by Evan Martin, a Google dev, as a resource to speed up the building of projects such as Chrome. Since its inception, some notable projects built using Ninja include Chrome, Android, all Meson projects, Swift, and LLVM.
For a very interesting review and tech analysis of the Ninja build system, Ninja’s creator wrote a critical review article eight years after its original release.
Ninja differs from other build systems in two major ways:
- It’s designed to have its input files generated by a higher-level build system such as CMake or Meson, and
- It’s designed to run builds as fast as possible.
This philosophy even goes into the default arguments, which are designed to provide the best performance with little to no tinkering. For example, it builds things in parallel by default. This motivates developers to ensure that their code can be built in parallel, and any problems can be detected early in the development process.
Next, we’ll take a closer look at the strengths and weaknesses of Ninja as a build system.
Advantages and Limitations of Ninja
The main advantage of Ninja is its speed in incremental builds. It incentivizes developers to write code that can be built in parallel, using defaults that utilize the -jN flag, which causes Ninja to build in parallel. Furthermore, Ninja doesn’t use a background daemon to constantly keep track of things in memory; it always starts its own binary from scratch and works without relying on any state. So developers will always have a realistic idea of build time without fancy background optimizations done by daemons, and it also makes Ninja very portable and simple.
According to benchmarks, Ninja performs as well as Make in a fresh build but outperforms it in an incremental build by what appears to be an exponentially increasing factor.
On the downside, Ninja can’t build projects without a build file, so it must always work with a build generator, such as CMake or Meson, the most popular build generators that work with Ninja. Problems can be introduced depending on the build generator used. For example, Make requires each file to be specified in the build file, making the process of writing these files extremely complicated, time consuming, and prone to errors. So, the key is to choose the right build generator that works well with Ninja.
When Should You Use Ninja?
Ninja works well for large projects with many files that need many incremental builds over a short time. If you’re already using Make, Meson, or CMake to generate build files and using Make to build them, Ninja is a plug-and-play replacement that will, at worst, keep the performance the same or, at best, improve it in an exponential manner in case of incremental builds.
Conversely, Ninja might not be a good choice if you want an end-to-end tool (build generator and tool in one) that has a high-level language to describe relationships between files and is also a build tool. In that case, something like Bazel might be better, but it’s often slower than Ninja and not as portable.
Implementing a Ninja Build

The following sections explain the different ways to install Ninja before going through step-by-step instructions for implementing a Ninja build.
How to Install Ninja
This section explains how to install Ninja on Linux, Mac, and Windows, and how to build it from source.
For a more thorough set of instructions for any specialized installation cases, please see the Ninja GitHub page, a very useful resource. For day-to-day use, the wiki page also includes a list of standard build patterns and build generators that work well with Ninja.
Installing Ninja on Linux
Depending on the Linux flavor, the installation process differs a bit:
- Arch:
pacman -S ninja - Debian/Ubuntu:
apt-get install ninja-build - Fedora:
dnf install ninja-build - Gentoo:
emerge dev-util/ninja - OpenSUSE:
zypper in ninja - Alpine:
apk add ninja
Installing Ninja on MacOS
Ninja can be installed using either Homebrew or MacPorts with the following one-liners:
- Homebrew:
brew install ninja - MacPorts:
port install ninja
Installing Ninja on Windows
Chocolatey or Scoop can be used to install Ninja with a one-liner on Windows:
- Chocolatey:
choco install ninja - Scoop:
scoop install ninja
Installing Ninja via Package Managers
Ninja can also be installed via package managers, which generally provide more convenience when managing multiple other packages in addition to it:
- Conda:
conda install -c conda-forge ninja - Pip:
python -m pip install ninja - Spack:
spack install ninja
Building Ninja From Source
Users who don’t want to build Ninja with specialized flags can build it from source with the following instructions.
First, clone and checkout the Ninja repo:
git clone git://github.com/ninja-build/ninja.git && cd ninja
git checkout releaseThen, build a basic Ninja binary and a set of files needed to build Ninja:
./configure.py --bootstrapThis will generate the Ninja binary and a build.ninja file that can be used to build Ninja with itself. That is, the basic Ninja binary generated in the previous step can be used to build the particular configuration of Ninja required. A sort of “ninjaception” if you will.
Use the following code to build Ninja:
cmake -Bbuild-cmake
cmake --build build-cmakeThe Ninja binary will now be inside the build-cmake directory (though the user can name this directory anything).
The following code will run the unit tests:
Creating a Project With Ninja

To demonstrate how to use Ninja as well as showcase some of its strengths, this tutorial uses a sample project, which can be found in this GitHub repo.
This tutorial will show you how to create a simple from-scratch project and an incremental project to demonstrate the time-saving features of Ninja.
Prerequisites
The following are prerequisites to follow along:
- CMake is required to build the project. Instructions for CMake installation can be found on their official website.
- For Linux users, CMake can be installed with the single terminal command
sudo snap install cmake --classic. It can be installed on macOS withbrew install cmake. - Python is required to generate the sample files used in this tutorial. Ensure Python is installed.
Creating a Project From Scratch
To create a project from scratch, do the following:
- Clone the repository with
git clone https://github.com/AntreasAntoniou/ninja-tutorial.git - Navigate to the project directory using
cd ninja-tutorial - Navigate to the from-scratch project using
cd scratch - Notice the two files inside this folder:
hello_world.cppandCMakeLists.txt
hello_world.cpp is a simple C++ program that prints “Hello World” to the console:
// C++ program to display "Hello World"
// Header file for input/output functions
#include <iostream>
using namespace std;
// main() function: where the execution of program begins
int main()
{
// Print "Hello World"
cout << "Hello World";
return 0;
}CMakeLists.txt is a CMake file that describes the project and how to build it:
cmake_minimum_required (VERSION 3.8)
project(HelloWorld CXX)
set(CMAKE_CXX_STANDARD 14)
add_executable(HelloWorld hello_world.cpp)Now use CMake to generate a build file for Ninja:
This should generate a build.ninja file in the current directory, along with related configuration files.
The project can now be built with Ninja using the following command:
The following output should be generated:
[2/2] Linking CXX executable HelloWorldWith that, the Ninja project should be successfully built.
Creating and Building an Incremental Project
Now, go back to the root of the repository and navigate to the incremental project by running:
There are three files here: hello_world-template.cpp, CMakeLists-template.txt, and generate_project_files.py.
The generate_project_files.py file is a Python script that generates the C++ project files and the CMake file from the template files.
This script needs to be run twice: once to generate a 1000-file project and a second time to generate a 1001-file project. So the second project will be an incremental build of the first.
Generate the 1000-file project first:
python3 generate_project_files.py --num_files 1000Now, use CMake to generate a build file for Ninja:
cmake -S sample_project -G NinjaThis should generate a build.ninja file in the current directory, along with related configuration files.
Build the project with Ninja:
Next, emulate an incremental build by adding one more file to your sample project:
python3 generate_project_files.py --num_files 1001Use CMake to generate a build file for Ninja:
cmake -S sample_project -G NinjaThis should generate a build.ninja file in the current directory, along with related configuration files.
As before, build the project with Ninja:
In the second build, Ninja only builds the new file and not the entire project. This can be seen in the terminal output that shows how many files had to be processed, as well as the time taken for the build to complete.
On the local setup (Apple M1 Max, 16-inch) used in this tutorial, the first build took 35 seconds, and the second build took three seconds.
The following is a copy of the terminal output for the second build:
❯ cmake -S sample_project/ -G Ninja
-- The CXX compiler identification is AppleClang 14.0.0.14000029
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: \
/Library/Developer/CommandLineTools/usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done
-- Generating done
-- Build files have been written to: \
/Users/helloworld/ninja-tutorial/incremental
ninja-tutorial/incremental on main [!+?] via △ v3.24.2 via 🐍 v3.9.13 \
on ☁️ took 4s
❯ ninja
[2000/2000] Linking CXX executable HelloWorld998
ninja-tutorial/incremental on main [!+?] via 🐍 v3.9.13 on ☁️ took 5m54s
❯ python generate_project_files.py --num_files 1001
Done
ninja-tutorial/incremental on main [!+?] via 🐍 v3.9.13 on ☁️
❯ cmake -S sample_project/ -G Ninja
-- Configuring done
-- Generating done
-- Build files have been written to: \
/Users/helloworld/ninja-tutorial/incremental
ninja-tutorial/incremental on main [!+?] via 🐍 v3.9.13 on ☁️ took 3s
❯ ninja
[2/2] Linking CXX executable HelloWorld1000As you can see, Ninja is able to build the updated 1001-file project in only three seconds, compared to the 35 seconds it took to build its predecessor project consisting of 1000 files. Because Ninja had already built the 1000-file variant of the same project, it only had to add one more file to the build.
Conclusion
So, we’ve dived deep into build systems and Ninja, covering how to install and use Ninja for your C++ projects. Remember, tools like build systems are your best pals for automating software building, testing, and deployment. Ninja is just one awesome tool that can save you heaps of time.
And if you loved Ninja, you might want to take a peek at Earthly for more build automation improvements.
Happy coding!
Earthly makes builds simple
Fast, repeatable builds with an instantly familiar syntax – like Dockerfile and Makefile had a baby.
Learn More
В этой статье я познакомлю вас с системой сборки с открытым исходным кодом, которая может помочь вам ускорить время компиляции при сборке проектов C ++.

Ninja — это легкая система сборки, предназначенная для использования преимуществ доступных ядер ЦП на вашем компьютере для эффективного создания исполняемых файлов и библиотек из исходного кода. Принцип его работы очень похож на GNU Make. То есть он принимает входные файлы, сгенерированные системой сборки высокого уровня, такой как CMake, и как можно быстрее превращает их в библиотеки и исполняемые файлы.
Следующее определение взято с официального сайта:
Ninja — это небольшая система сборки, ориентированная на скорость. Он отличается от других систем сборки в двух основных отношениях: он предназначен для того, чтобы его входные файлы генерировались системой сборки более высокого уровня, и он предназначен для максимально быстрого запуска сборки.
Установить
Вы можете установить Ninja с помощью менеджеров пакетов:
Linux
- Debian / Ubuntu:
apt-get install ninja-build - Арка:
pacman -S ninja - Fedora:
dnf install ninja-build
Mac
- HomeBrew:
brew install ninja - MacPorts:
port install ninja
Или соберите исходный код, загрузив один из релизов из репозитория Github. Последний выпуск 1.9.0 содержит готовые предварительно скомпилированные двоичные файлы для 64-битных Linux, Mac OS X и Windows.
Привет, мир!
Разница между Ninja и другими системами сборки заметна при создании больших проектов. Однако давайте посмотрим на следующей демонстрации, как Ninja работает с CMake. Давайте создадим эту простую программу HelloWorld:
После создания исходного кода мы переходим к созданию для него файла CMakeLists.txt. Назовем наш проект HelloWorld и установим версию C ++ на 14. CMakeLists.txt будет выглядеть так:
Чтобы сгенерировать файлы сборки Ninja, нам нужно запустить CMake с флагом -G Ninja. Выполните в терминале следующую команду:
$ cmake -G NinjaCMake сгенерирует собственные файлы кеша / настроек, build.ninja и rules.ninja. На этом изображении показаны выходные файлы:

После создания необходимых конфигураций мы можем начать сборку проекта, просто набравninja:
$ ninjaВы должны увидеть исполняемый файл с именем HelloWorld, созданный в каталоге, как показано на этом изображении:

Инкрементальная сборка
В следующий раз, когда мы изменим код, нам не нужно будет запускать команду для CMake. Все, что нам нужно, это снова набрать ninja, и запускается новая сборка.
Более того, Ninja использует модель инкрементальной сборки, то есть в проектах с несколькими исходными файлами перестраиваются только измененные файлы. Он не восстанавливает то, что уже обновлено. Эта оптимизация значительно сокращает время сборки.
Понравилась история?
Хлопайте в ладоши, подписывайтесь на меня на Medium и Twitte r и попробуйте Ninja, когда у вас будет время. Обратная связь всегда приветствуется!
Обо мне
Меня зовут Ильяс Хамадуш, старший инженер-программист компании Elektrobit Automotive. Интересуюсь автомобильным программным обеспечением и встроенными системами. Следуйте за мной в Twitter и LinkedIn.
Время на прочтение
12 мин
Количество просмотров 9.1K
 Привет, Хабр!
Привет, Хабр!
Недавно я задумался, ковыряя очередную бесплатную систему сборки, «А нельзя ли взять и самому написать такую систему? Ведь это просто — взять ту же Ninja, прикрутить разделение на препроцессинг и компиляцию, да и передавать по сети файлы туда-сюда. Куда уж проще?»
Просто — не просто, как самому сделать подобную систему — расскажу под катом.
Этап 0. Формулировка задачи
Disclaimer: Статья отмечена как tutorial, но это не совсем пошаговое руководство, скопипастив код из которого получится готовый продукт. Это скорее инструкция — как спланировать и куда копать.
Сперва определимся, какой общий алгоритм работы должен получиться:
- Читаем граф сборки, вычленяем команды компиляции;
- Разбиваем компиляцию на два этапа, препроцессинг и собственно генерацию кода. Последнюю помечаем как возможную к удаленному выполнению;
- Выполняем препроцессинг, считываем результат в память;
- Отправляем препроцессированный файл и команду на генерацию кода на другой хост по сети;
- Выполняем команду кодогенерации, считываем объектный файл и отдаем в качестве ответа по сети;
- Полученный объектный файл сохраняем на диск и выводим в консоль сообщения компилятора.
Вроде не так и страшно, верно? Но сходу за вечер написать все это, пожалуй, не выйдет. Сперва напишем несколько прототипов, и статья рассказывает о них:
- Прототип 1. Программа имитирует компилятор, разделяя команду на 2, и самостоятельно вызывая компилятор.
- Прототип 2. К этому добавим пересылку команды на компиляцию по сети, без самого файла.
- Прототип 3. Пройдемся по графу сборки Ninja, выводя потенциально разбиваемые команды.
Рекомендуется разработку прототипа делать под POSIX-совместимой OS, если вы не будете пользоваться библиотеками.
Этап 1. Разбиваем командную строку
Для прототипа остановимся на компиляторе GCC (или Clang, нет большой разницы), т.к. его командную строку проще разбирать.
Пусть у нас программа вызывается через команду «test -c hello.cpp -o hello.o». Будем считать, что после ключа «-c» (компиляция в объектный код) всегда идет имя входного файла, хоть это и не так. Так же пока остановимся только на работе в локальной директории.
Мы будем использовать функцию popen для запуска процесса и получения стандартного вывода. Функция позволяет открыть процесс так же, как мы бы открыли файл.
Файл main.cpp:
#include <iostream>
#include "InvocationRewriter.hpp"
#include "LocalExecutor.hpp"
int main(int argc, char ** argv)
{
StringVector args;
for (int i = 1; i < argc; ++i)
args.emplace_back(argv[i]);
InvocationRewriter rewriter;
StringVector ppArgs, ccArgs; // аргументы для препроцессинга и компиляции соотвественно.
if (!rewriter.SplitInvocation(args, ppArgs, ccArgs))
{
std::cerr << "Usage: -c <filename> -o <filename> \n";
return 1;
}
LocalExecutor localExecutor;
const std::string cxxExecutable = "/usr/bin/g++"; // предполагаем, что мы работаем под GNU/Linux.
const auto ppResult = localExecutor.Execute(cxxExecutable, ppArgs);
if (!ppResult.m_result)
{
std::cerr << ppResult.m_output;
return 1;
}
const auto ccResult = localExecutor.Execute(cxxExecutable, ccArgs);
if (!ccResult.m_result)
{
std::cerr << ccResult.m_output;
return 1;
}
// не учтен вариант, что есть стандартный вывод, но результат успешен.
return 0;
}
Код InvocationRewriter.hpp
#pragma once
#include <string>
#include <vector>
#include <algorithm>
using StringVector = std::vector<std::string>;
class InvocationRewriter
{
public:
bool SplitInvocation(const StringVector & original,
StringVector & preprocessor,
StringVector & compilation)
{
// Найдем сперва позиции аргументов -c и -o.
// Будем считать, что после -c всегда идет имя входного файла, хоть это и не так.
const auto cIter = std::find(original.cbegin(), original.cend(), "-c");
const auto oIter = std::find(original.cbegin(), original.cend(), "-o");
if (cIter == original.cend() || oIter == original.cend())
return false;
const auto cIndex = cIter - original.cbegin();
const auto oIndex = oIter - original.cbegin();
preprocessor = compilation = original;
const std::string & inputFilename = original[cIndex + 1];
preprocessor[oIndex + 1] = "pp_" + inputFilename; // абсолютные имена не поддерживаются
preprocessor[cIndex] = "-E"; // вместо компиляции - препроцессинг.
compilation[cIndex + 1] = "pp_" + inputFilename;
return true;
}
};
Код LocalExecutor.hpp
#pragma once
#include <string>
#include <vector>
#include <algorithm>
#include <stdio.h>
using StringVector = std::vector<std::string>;
class LocalExecutor
{
public:
/// Результат выполнения команды: стандартный вывод + результат
struct ExecutorResult
{
std::string m_output;
bool m_result = false;
ExecutorResult(const std::string & output = "", bool result = false)
: m_output(output), m_result(result) {}
};
/// выполняет команду с помощью popen.
ExecutorResult Execute(const std::string & executable, const StringVector & args)
{
std::string cmd = executable;
for (const auto & arg : args)
cmd += " " + arg;
cmd += " 2>&1"; // объединим sterr и stdout.
FILE * process = popen(cmd.c_str(), "r");
if (!process)
return ExecutorResult("Failed to execute:" + cmd);
ExecutorResult result;
char buffer[1024];
while (fgets(buffer, sizeof(buffer)-1, process) != nullptr)
result.m_output += std::string(buffer);
result.m_result = pclose(process) == 0;
return result;
}
};
Что ж, теперь у нас есть маленький эмулятор компилятора, который дергает настоящий компилятор. Едем дальше 
Дальнейшее развитие прототипа:
- Учитывать и абсолютные имена файлов;
- Использовать одну из библиотек для работы с процессами: Boost.Process, QProcess, или Ninja Subprocess;
- Реализовать поддержку разделения команд для MSVC;
- Сделать API для выполнения команд асинхронным, а выполнение вынести в отдельный поток.
Этап 2. Сетевая подсистема
Прототип сетевого обмена сделаем на BSD Sockets (Сокеты Беркли)
Немного теории:
Сокет это дословно «дырка», в которую можно писать данные и считывать из неё. Чтобы подключиться к удаленному серверу, алгоритм следующий:
- Создать сокет нужного типа (TCP) с помощью функции socket();
- После создания, выставить нужные флаги, например неблокирующий режим с помощью setsockopt();
- Получить адрес в нужном формате для BSD сокетов с помощью getaddrinfo();
- Подключиться к TCP-хосту с помощью функции connect(), передав туда подготовленный адрес;
- Вызывать функции read/send для чтения и записи;
- После окончания работы — вызвать close().
Сервер работает немного сложнее:
- Создаем сокет с помощью функции socket();
- Выставляем опции;
- Вызываем bind() для того, чтобы привязать сокет к определённому адресу (полученному через getaddrinfo)
- Начинаем прослушку порта с помощью вызова listen();
- Входящие соединения примаем функцией accept() — он возвращает нам новый сокет;
- С полученным сокетом выполняем операции read/write;
- Закрываем сокет соединения и сокет прослушки через close().
Нам понадобятся сокет-клиент и сокет-сервер. Пусть их интерфейс выглядит следующим образом:
/// Интерфейс сокета
class IDataSocket
{
public:
using Ptr = std::shared_ptr<IDataSocket>;
/// Результаты чтения и запаси. Success- Успешно, TryAgain - данные не были прочитаны либо записаны, Fail - сокет был закрыт.
enum class WriteState { Success, TryAgain, Fail };
enum class ReadState { Success, TryAgain, Fail };
public:
virtual ~IDataSocket() = default;
/// Подключение к удаленному хосту
virtual bool Connect () = 0;
/// Закрытие соединение
virtual void Disconnect () = 0;
/// Проверки статуса соединения - подключен; сейчас подключается
virtual bool IsConnected () const = 0;
virtual bool IsPending() const = 0;
/// Читаем данные из сокета в буфер
virtual ReadState Read(ByteArrayHolder & buffer) = 0;
/// Пишем данные в сокет.
virtual WriteState Write(const ByteArrayHolder & buffer, size_t maxBytes = size_t(-1)) = 0;
};
/// интерфейс "слушателя". Он может создавать сокеты при подключении.
class IDataListener
{
public:
using Ptr = std::shared_ptr<IDataListener>;
virtual ~IDataListener() = default;
/// Получение следующего соединения
virtual IDataSocket::Ptr GetPendingConnection() = 0;
/// Начало прослушивания порта:
virtual bool StartListen() = 0;
};
Реализацию данного интерфейса я не буду вставлять в статью, вы можете ее сделать самостоятельно либо подсмотреть вот здесь.
Допустим, сокет у нас готов, как будет примерно выглядеть клиент и сервер компилятора?
Сервер:
#include <TcpListener.h>
#include <algorithm>
#include <iostream>
#include "LocalExecutor.hpp"
int main()
{
// Создадим настройки для подключения.
TcpConnectionParams tcpParams;
tcpParams.SetPoint(6666, "localhost");
// Создадим прослушку на порту 6666;
auto listener = TcpListener::Create(tcpParams);
IDataSocket::Ptr connection;
// Дождемся первого входящего соединения;
while((connection = listener->GetPendingConnection()) == nullptr) ;
// Подключим соединение и прочитаем все данные.
connection->Connect();
ByteArrayHolder incomingBuffer; //!< просто обертка над std::vector<uint8_t>;
while (connection->Read(incomingBuffer) == IDataSocket::ReadState::TryAgain) ;
// Считая, что в качестве данных нам пришла команда, выполним её.
std::string args((const char*)(incomingBuffer.data()), incomingBuffer.size());
std::replace(args.begin(), args.end(), '\n', ' ');
LocalExecutor localExecutor;
const auto result = localExecutor.Execute("/usr/bin/g++", StringVector(1, args));
std::string stdOutput = result.m_output;
if (stdOutput.empty())
stdOutput = "OK\n"; // небольшой хак - если результат выполнения пустой, отправим хотя бы OK.
// запишем в подключившийся сокет результат выполнения команды.
ByteArrayHolder outgoingBuffer;
std::copy(stdOutput.cbegin(), stdOutput.cend(), std::back_inserter(outgoingBuffer.ref()));
connection->Write(outgoingBuffer);
connection->Disconnect();
// Можно не выходить здесь, а вынести обработку соединений в отдельный поток.
// А потом и обработку чтения/записи из каждого подключения в отдельный поток.
return 0;
}
Клиент:
#include <iostream>
#include <TcpSocket.h>
#include "InvocationRewriter.hpp"
#include "LocalExecutor.hpp"
int main(int argc, char ** argv)
{
StringVector args;
for (int i = 1; i < argc; ++i)
args.emplace_back(argv[i]);
InvocationRewriter rewriter;
StringVector ppArgs, ccArgs; // аргументы для препроцессинга и компиляции соотвественно.
if (!rewriter.SplitInvocation(args, ppArgs, ccArgs))
{
std::cerr << "Usage: -c <filename> -o <filename> \n";
return 1;
}
LocalExecutor localExecutor;
const std::string cxxExecutable = "/usr/bin/g++"; // предполагаем, что мы работаем под GNU/Linux.
const auto ppResult = localExecutor.Execute(cxxExecutable, ppArgs);
if (!ppResult.m_result)
{
std::cerr << ppResult.m_output;
return 1;
}
// Подключимся к серверу на порт 6666
TcpConnectionParams tcpParams;
tcpParams.SetPoint(6666, "localhost");
auto connection = TcpSocket::Create(tcpParams);
connection->Connect();
ByteArrayHolder outgoingBuffer;
for (auto arg : ccArgs)
{
arg += " "; // разделим аргументы пробелом и вставим в буфер.
std::copy(arg.cbegin(), arg.cend(), std::back_inserter(outgoingBuffer.ref()));
}
connection->Write(outgoingBuffer);
ByteArrayHolder incomingBuffer;
while (connection->Read(incomingBuffer) == IDataSocket::ReadState::TryAgain) ;
std::string response((const char*)(incomingBuffer.data()), incomingBuffer.size());
if (response != "OK\n")
{
std::cerr << response;
return 1;
}
return 0;
}
Да, не все исходники показаны, например TcpConnectionParams или ByteArrayHolder, но это достаточно примитивные структуры.
После отладки этого прототипа, у нас есть небольшой сервис, который может локально компилировать препроцессированные файлы (при некоторых допущениях, например, что рабочая директория клиента и сервера совпадают).
Дальнейшее развитие прототипа:
- Настоятельно рекомендую использовать одну из существующих сетевых библиотек — Boost.Asio, QTcpSocket (QtNetwork), так же подумать над сериализацией с помощью Protobuf или других подобных
- Реализовать передачу файлов по сети. Скорее всего, придется их разбивать на фрагменты, но будет зависеть от выбранной вами библиотеки.
- Необходимо задуматься об асинхронном API отправки и приема сообщений. Кроме того, желательно его сделать абстрактным и не привязанным к сокетам вообще.
Этап 3. Интеграция с Ninja
Для начала, необходимо ознакомиться с принципами работы Ninja. Предполагается, что вы уже собирали с её помощью какие-либо проекты и примерно представляете, как выглядит build.ninja.
Используемые понятия:
- Узел (Node) — это просто файл. Входной (исходники), выходной (объектные файлы) — это все узлы или вершины графа.
- Правило (Rule) — по сути это просто команда с шаблоном аргументов. Например, вызов gcc — правило, а его аргументы — $FLAGS $INCLUDES $DEFINES и еще какие-то общие аргументы.
- Ребро (Edge). Для меня было немного удивительно, но ребро соединяет не два узла, а несколько входных узлов и один выходной, посредством Правила. Вся система сборки основана на том, что последовательно обходит граф, выполняя команды для ребер. Как только все ребра обработаны, проект собран.
- Состояние (State) — это контейнер со всем вышеперечисленным, который система сборки и использует.
Как это примерно выглядит, если нарисовать зависимости:
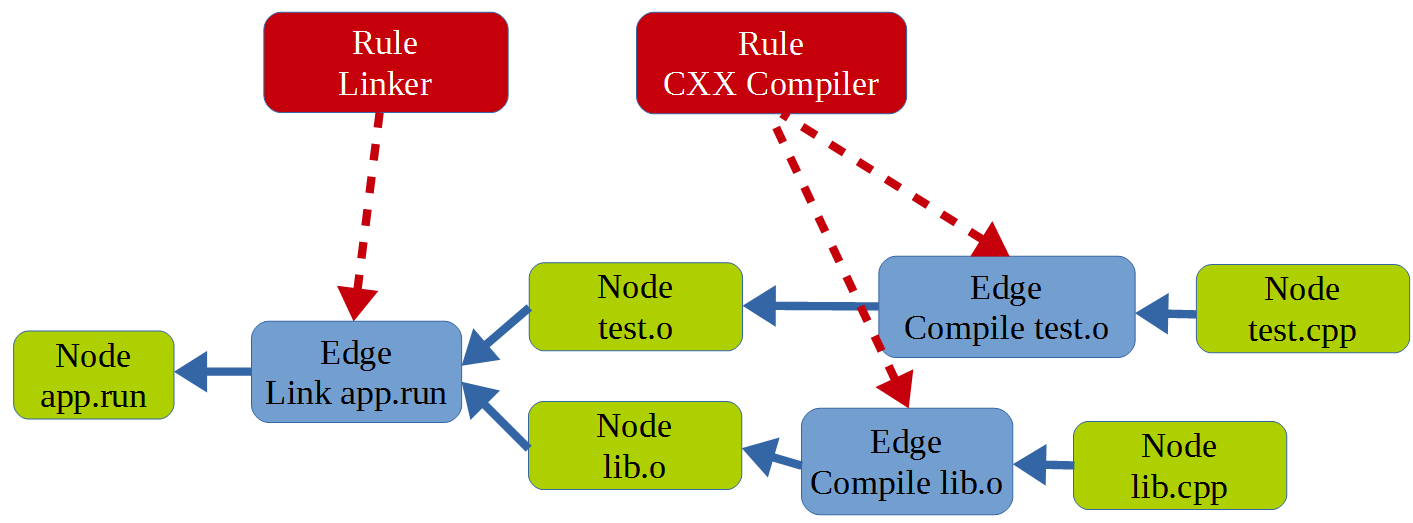
Здесь показан граф сборки для двух единиц трансляции, которые компонуются в приложение.
Как мы видим, для того, чтобы внести свои изменения в систему сборки, нам нужно переписать State, разбив Edges на два в нужных местах и добавив новые узлы (препроцессированные файлы).
Предположим, у нас уже есть исходники ninja, мы их собираем, и все в собранном виде работает.
Добавим в ninja.cc следующий фрагмент кода:
// Limit number of rebuilds, to prevent infinite loops.
const int kCycleLimit = 100;
for (int cycle = 1; cycle <= kCycleLimit; ++cycle) {
NinjaMain ninja(ninja_command, config);
ManifestParser parser(&ninja.state_, &ninja.disk_interface_,
options.dupe_edges_should_err
? kDupeEdgeActionError
: kDupeEdgeActionWarn);
string err;
if (!parser.Load(options.input_file, &err)) {
Error("%s", err.c_str());
return 1;
}
// граф сборки уже загружен, теперь модифицируем его:
RewriteStateRules(&ninja.state_); // вот этот вызов
Саму функцию RewriteStateRules можно унести в отдельный файл, либо объявить здесь же, в ninja.cc как:
#include "InvocationRewriter.hpp"
// Структура, которая описывает замену правил Ninja.
struct RuleReplace
{
const Rule* pp;
const Rule* cc;
std::string toolId;
RuleReplace() = default;
RuleReplace(const Rule* pp_, const Rule* cc_, std::string id) : pp(pp_), cc(cc_), toolId(id) {}
};
void RewriteStateRules(State *state)
{
// скопируем текущие правила, т.к. будет не очень хорошо, когда мы будем модифицировать этот контейнер.
const auto rules = state->bindings_.GetRules();
std::map<const Rule*, RuleReplace> ruleReplacement;
InvocationRewriter rewriter;
// пройдем по всем существующим правилам
for (const auto & ruleIt : rules)
{
const Rule * rule = ruleIt.second;
const EvalString* command = rule->GetBinding("command");
if (!command) continue;
// сформируем команду для нашего rewriter-а.
std::vector<std::string> originalRule;
for (const auto & strPair : command->parsed_)
{
std::string str = strPair.first;
if (strPair.second == EvalString::SPECIAL)
str = '$' + str;
originalRule.push_back(str);
}
// попробуем разделить команду:
std::vector<std::string> preprocessRule, compileRule;
if (rewriter.SplitInvocation(originalRule, preprocessRule, compileRule))
{
// создадим 2 копии rule - rulePP и ruleCC, заменим их bindings_ на новые команды.
// занесем новые правила в ruleReplacement (ruleReplacement[rule] = ...)
}
}
const auto paths = state->paths_;
std::set<Edge*> erasedEdges;
// пройдем по всем узлам графа
for (const auto & iter : paths)
{
Node* node = iter.second;
Edge* in_egde = node->in_edge();
if (!in_egde)
continue;
// получим входное ребро и соответствующее ему правило.
// если правило необходимо разбить на два, сделаем это:
const Rule * in_rule = &(in_egde->rule());
auto replacementIt = ruleReplacement.find(in_rule);
if (replacementIt != ruleReplacement.end())
{
RuleReplace replacement = replacementIt->second;
const std::string objectPath = node->path();
const std::string sourcePath = in_egde->inputs_[0]->path();
const std::string ppPath = sourcePath + ".pp"; // лучше сделать отдельный метод для имен файлов.
Node *pp_node = state->GetNode(ppPath, node->slash_bits());
// Создадим два новых ребра
Edge* edge_pp = state->AddEdge(replacement.pp);
Edge* edge_cc = state->AddEdge(replacement.cc);
// ... код пропущен ...
// поместим входы исходного ребра во входы edge_pp;
// выходы исходного ребра в выходы edge_cc
// а в середине вставим pp_node.
// кроме того, особо отметим edge_cc, что может выполняться удалённо -
// например, добавив поле:
edge_cc->is_remote_ = true;
// после всех манипуляций, очистим исходное ребро.
in_egde->outputs_.clear();
in_egde->inputs_.clear();
in_egde->env_ = nullptr;
erasedEdges.insert(in_egde);
}
}
// удалим лишние ребра.
vector<Edge*> newEdges;
for (auto * edge : state->edges_)
{
if (erasedEdges.find(edge) == erasedEdges.end())
newEdges.push_back(edge);
}
state->edges_ = newEdges;
}
Некоторые нудные фрагменты вырезаны, полный код можно посмотреть здесь.
Доработка прототипа:
- Скорее всего, первый вариант InvocationRewriter не заработает, нужно будет учитывать много вещей — например, то что аргумент компиляции «-c» может быть задан » -c «, ну и я уже молчу про то что он не обязательно предваряет исходный файл.
- Может быть много дополнительных флагов, которые отмечают какие-то файлы, так что не всё то, что «не флаг» — это файл.
- После создания разделённого графа, если он успешно собирается в две фазы «препроцессинг и компиляция» — нужно будет проинтегрировать удаленное выполнение по сети с нашим сетевым слоем. Собственно цикл сборки в Ninja находится в build.cc в функции Builder::Build. В нее можно добавить по аналогии с
«if (failures_allowed && command_runner_->CanRunMore())» и «if (pending_commands)» свои этапы для распределённой сборки.
Этап X. Что дальше?
После успешного создания прототипа, нужно двигаться маленькими шажками к созданию продукта:
- Конфигурирование всех модулей — как сетевой подсистемы, так и InvocationRewriter-а;
- Поддержка любых комбинаций опций под разными компиляторами;
- Поддержка сжатия при передаче файлов;
- Разнообразная диагностика в виде логов;
- Написание координатора, который сможет обслуживать подключение к нескольким серверам сборки;
- Написание балансировщика, который будет учитывать то, что серверами пользуется сразу несколько клиентов (и не перегружать их сверх меры);
- Написать интеграцию с другими системами сборки, не только Ninja.
В общем, ребята, я остановился где-то на этом этапе; сделал OpenSource-проект Wuild (исходники тут), лицензия Apache, который все эти штуки реализует. На написание ушло примерно 150 часов свободного времени (ежели кто решится повторить мой путь). Я настоятельно рекомендую по максимуму использовать существующие свободные библиотеки, чтобы сконцентрироваться на бизнес-логике и не отлаживать работу сети или запуск процессов.
Что умеет Wuild:
- Распределённая сборка с возможностью кросс-компиляции (Clang) под Win, Mac, Linux;
- Интеграция с Ninja и Make.
Да в общем и всё; проект в состоянии между альфой и бетой (стабильность — есть, фич — нет  ). Бенчмарков не выкладываю (рекламировать не хочу), но, в сравнении с одним из продуктов-аналогом, скорость меня более чем устроила.
). Бенчмарков не выкладываю (рекламировать не хочу), но, в сравнении с одним из продуктов-аналогом, скорость меня более чем устроила.
Статья носит скорее образовательный характер, а проект — предостерегательный (как делать не надо, в смысле NIH-синдрома — делайте меньше велосипедов).
Кто хочет — форкайте, делайте пулл-реквесты, используйте в любых страшных целях!
Search code, repositories, users, issues, pull requests…
Provide feedback
Saved searches
Use saved searches to filter your results more quickly
Sign up