
This article is a comprehensive guide on how to read the contents of your computer’s RAM.
Random Access Memory (RAM) is a crucial component of any computer system, and it is responsible for temporarily storing data that is required by the system to carry out its functions. But the contents of RAM can be quite volatile, and they are usually lost when the system is shut down.
One way to preserve the contents of RAM is by performing a RAM dump, which is a process of copying the contents of RAM onto a storage device, such as a hard drive. You can analyze the RAM dump, and the data contained within it can provide valuable insights into the system’s state at the time the dump was taken.
In this article, I will walk you through the process of reading the contents of RAM, as well as explain what a RAM dump is and how it can be useful in analyzing a computer system. I will also provide you with step-by-step instructions on how to perform a RAM dump and how to analyze the resulting data.
Why Read RAM Data?
Reading data from the disc is something you might be familiar with doing. But can we also read data straight from the RAM, where the most essential information is stored?
As developers, we can investigate the space complexity and delve further into the RAM to understand what is going on.
Accessing and reading the contents of RAM can be useful in a variety of scenarios. One common use case is for troubleshooting and diagnosing issues with a computer system. By examining the contents of RAM, you can gain insights into the state of the system at a particular point in time.
For example, if your computer suddenly crashes, examining the contents of RAM can help you identify the cause of the crash.
Another use case is for forensic analysis. When investigating a computer system for evidence of wrongdoing, examining the contents of RAM can provide valuable insights into the activities that were being carried out on the system.
For example, a security professional may use RAM analysis to determine whether a particular process was running on the system or to identify files that were recently accessed.
In addition, accessing and reading the contents of RAM can also be useful for software developers and researchers. By analyzing the data stored in RAM, developers can gain insights into the performance of their software and identify potential issues or bottlenecks. Researchers can also use RAM analysis to study the behavior of malware or to develop new security tools and techniques.
Overall, accessing and reading the contents of RAM can be useful for troubleshooting, forensic analysis, software development, and research. It provides a valuable way to gain insights into the inner workings of a computer system and can help identify issues and potential security threats.
Before we move further into the specifics, let’s take a short look at the nomenclature. This may be common knowledge, but you’ll need to understand the terminology as you go through this guide, so it’s worth a review.
There’s a physical hardware device called RAM (which stands for Random Access Memory): the physical memory, a CPU, a hard disk, and other physical components.
On top of this, we have the operating system. The operating system is always in conversation with the piece of hardware known as the «kernel» – and this is one of the most critical aspects of this software.
If we consider things from the user’s point of view, we initially log in to the operating system so that we can carry out our tasks, the majority of which include executing applications.
What is the Kernel?
A kernel is a fundamental portion of an operating system that accepts the instructions from the user with the aid of the program we run behind the scenes. This may happen regardless of the program that we run behind the scenes.
Everything that has to be computed is handled by the central processing unit (CPU), but whatever we do and however we manage the services provided by the CPU, the data, instructions, code, and program must all go via the random access memory (RAM).
This implies that the results of anything we do with the data at any given moment in time will be available on top of the memory. If you are a programmer and you’re constructing some kind of data structure, this indicates that all of the data will live on top of the RAM.
We can directly go to the RAM and see how the data structures have been created and how they align, and we can see how the space complexity works there.
For instance, if we are discussing any web browser, such as Chrome, there may have been security flaws generated in an application. So the most effective method is to navigate to the RAM and investigate how the data has been operating.
Let’s say you open any secure website in Chrome (or any browser), like gmail.com. Any information you enter into Gmail, including your username and password, is sent over the internet to a server run by Google. That data has been fully encrypted, and it will be challenging, if not impossible, to crack the password.
But in order to enter your password, you likely use a computer with a keyboard attached to it. After that, some programs will encrypt the data and send it to the internet. This means that initially, your data was present in the RAM.
First, the password is standard data, and the password goes and lands on the top of the RAM. Then, some programs will encrypt the data and send it to the internet. If you can access the RAM, you can examine it to determine whether or not your password has been encrypted. And this process is pretty straightforward.
Let’s look at an example to see how this works. We’ll pretend that «a» is a variable and «9» is the data. When we execute the program, this data loads onto the RAM. When the program ends, the data from the RAM will be gone, although nobody has proven it yet. But this is the case, and we can prove it with a little investigation.
So how can we check whether or not this data is still present in the RAM after the application has finished running if it was loaded at the very top of the memory?
Well, the RAM will be cleared of these contents shortly. A «RAM dump» is the process of capturing all of the RAM. This demonstrates the actual form in which the entire data set is made accessible and loaded onto the RAM for the first time. And you’ll learn how to capture or extract the data from memory next.
In order to accomplish this, you’ll need some form of software. As a result, the goal of this program is to travel further into the memory. It will go into memory and retrieve all of the stored data from memory before continuing.
What is LiME?
The Linux memory extractor, sometimes referred to as LiME, is a powerful piece of software. It’s what you use to extract the memory from Linux. This piece of software is also known as the driver, also referred to as the module. This is because RAM is a device, which complicates things further.
We need some form of driver to access the device so we can try to read the contents of it. LiME is an example of a driver, and if you’re familiar with Linux you may know that in order to make any driver function, you need to load that driver with the assistance of the kernel.
Within the context of Linux, a driver is also referred to as a module. So LiME is a Linux kernel module. We have access to what is known as a kernel loadable module, which allows us to install the module on the operating system.
We have covered enough background. Now, let’s look at how we can extract the contents of the RAM. We’ll go through the process step-by-step in a hands-on way.
Setup and Installations
So, the only thing we need is the LiME driver. Here’s the link to download this particular module: https://github.com/gursimarsm/LiME.
Now, boot up your Linux system (I use RedHat Enterprise Linux). You can use the free -h command to check the amount of RAM memory that’s being used, that’s available, and other details. Mine looks like this:

free -m command
To access RAM, we need some software where the kernel can load some extra modules. In our case, the module name is LiME. So, the software we install are called “kernel-devel”, and “kernel-headers”. These two pieces of software are what we need to install in order to perform our subsequent actions, that is to use the LiME module.
If you want to install the software, you should have «yum» configured. For context, yum is a command you can use to install the software in the RedHat Linux operating system. I’ll demo how to configure it in the appendix for reference.

So, now that you’ve installed that software, you need one more piece of software because you have to download some drivers from GitHub. So, now you need to install Git if you don’t already have it. You can do this using the command yum install git. You also need to configure your account so that you can work with it.
# git config --global user.name "Your Name"
# git config --global user.email "you@example.com" I shared the repository above. It’s a loadable kernel module (LKM). It lets you acquire the entire memory from your Linux operating system or any kind of language operating system (including Android devices because Android is based on Linux as well).
You can download the module using the # git clone https://github.com/gursimarsm/LiME command.
After downloading that, you need to move into the directory of the software. You’ll find multiple folders there. But, to run the main code, you need to move to the «src» directory.
In this directory, you’ll find multiple programs based on the C language. So, in order to make use of the files, you’ll need to compile them. To do that, you can use the make command. Install that like this:
# yum install make
# yum install gcc In the directory /LiME/src/, run the make command to compile the entire code.
If you encounter an error, it might be because we are using the latest version of LiME, and it comes with a new feature called orc metadata generate. To implement this feature, you have to install one more thing that’s part of LiME called elfutils-libelf-devel. You can do that using yum like you can see below:
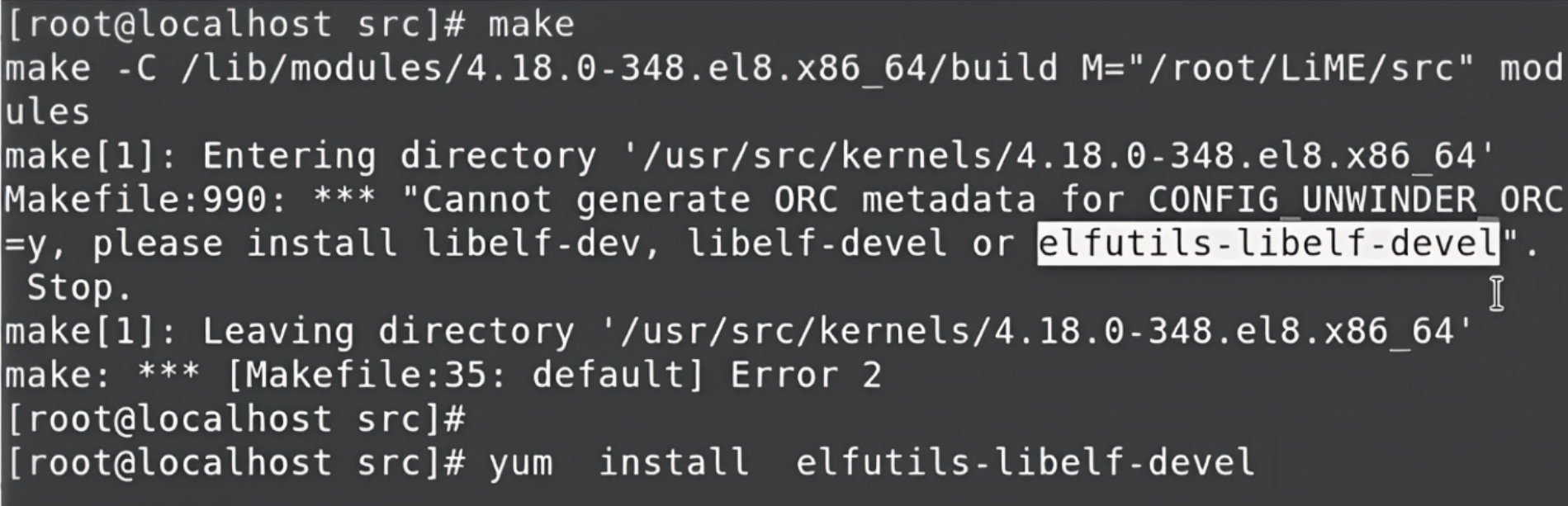
elfutils-libelf-devel
After that’s done, if we now run the make command it will ask the GCC compiler to compile the entire code. After the compilation, it will create one final object file called the kernel object file, and that is the final module in LiME.

You can find this file in the same directory by using the ls command.
How to Use the Module
With this module, the kernel now has the capability to capture or read the entire RAM. By default, we can’t read the entire RAM in one go, but now because of the LiME module, we can.
To learn more about the LiME module, you can use the modinfo command. Type modinfo along with lime. This will show you some more details like where the file is available, and it also displays all the modules or drivers that come with some kind of extra parameters. Every parameter has some benefits.
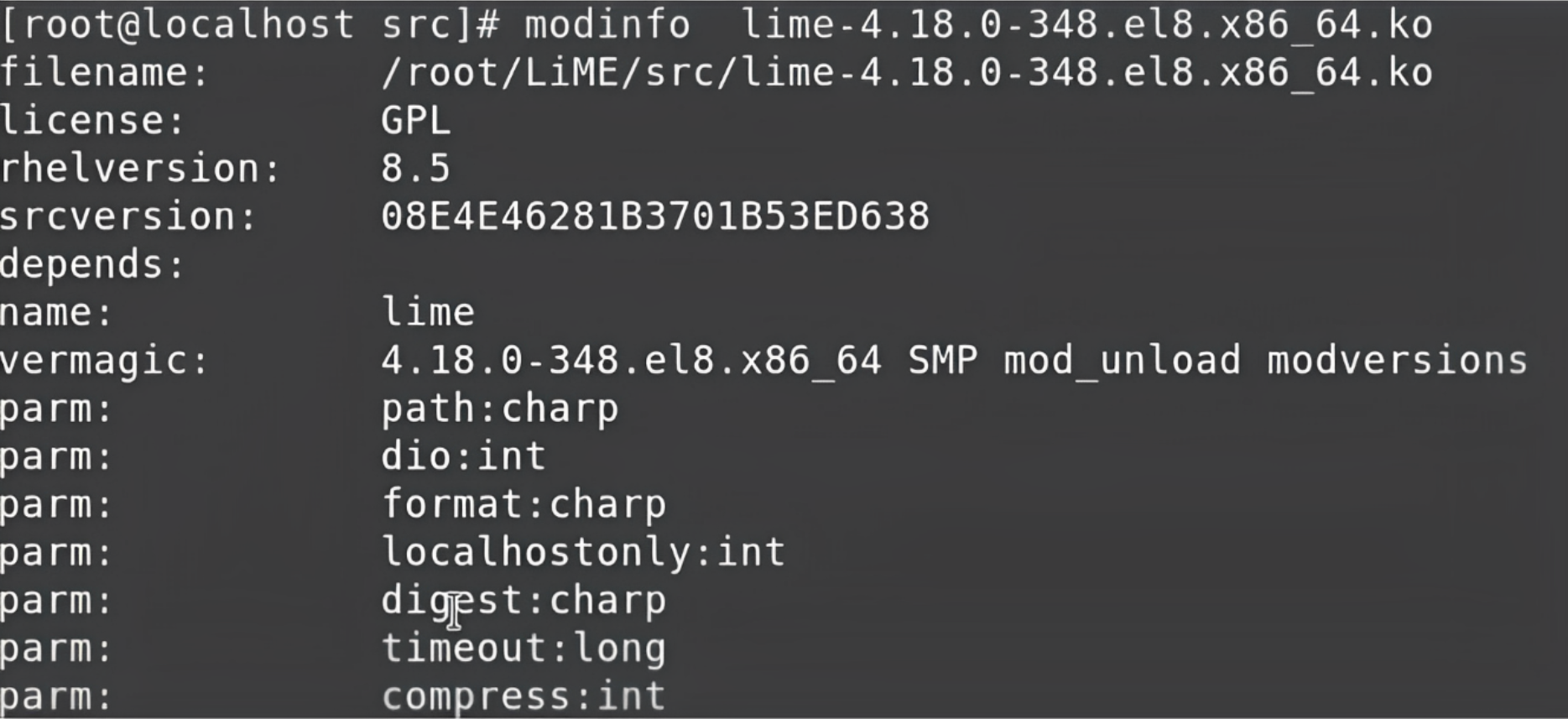
Here we are going to use two parameters which are very important: path and format.
path means when we read the entire RAM, we have to store the data of the RAM in some file. So, to specify the destination file we would like to create, we have to give that particular information over here.
The next parameter, format, specifies the format in which we want to read the RAM data. So, in this case, we want to read the format of the RAM as it is. The data stored in the RAM is mostly in binary, and we want to read the entire data in that binary format only and capture it in its raw form.
So, the format will be raw and stored in the file wherever we give the path.
Finally, it’s time to read the data from the RAM. So, let’s come to the main command that will help us start reading the entire RAM.
Demonstration
Type in your password for your Gmail account in Chrome for this demonstration. This will help you learn how to capture the data from the RAM and also if your password is encrypted.
To verify these two things, move to the command prompt and check if the data is still on the RAM. You’ll have to load a particular module using the command insmod. This will help you insert the module.
Copy the complete path of the module and paste it along with the insmod command.

insmod command
This module will get loaded with the help of the kernel. The module will start capturing the entire data from the RAM and it’ll store it in a file, for example, myram.data
It will also load the entire memory dump or RAM dump into this file and which format we want to capture. So, the format will be the raw format.
We’ll use these two parameters (don’t worry about this for now). We need only two parameters to perform, and now as soon as we hit this command, whatever data we have will be captured and stored in this particular file. This command typically takes a few seconds, depending on the CPU speed and the amount of data we have in the RAM.

How to read the data
Now, we have this file myram.data and the entire data of the RAM is stored in this file. Because we captured this data in the raw format, the data is going to be in binary. If we try to read this data from this file directly, as human beings, we can’t read it even if we try it with the initial lines using the head command to read some of the top 10 lines.
So, we can use the “cat” command, which will read the entire data. But, again, the same thing is going to happen – it will read the entire data, but the data will be displayed in the binary format. Then we need to use the pipe function with this command and combine it with another new command called strings:

String is a command that will convert the data into regular text in a human-readable format.
The list will go on and on. You can interrupt it using Ctl+C.
Right now, it won’t mean much seeing and reading the entire data. We know some data that are there on the RAM is the password called mywebpasswordgmail. So, just to confirm that this data is available on the RAM we can use one more pipe along with the grep command. The grep command helps us sort the data.
cat /myram.data | strings | grep mywebpasswordgmail Now, we are searching for this string in the entire data. It will convert the data into regular text, and wherever that particular string shows up, grep will grab that line and let us start searching, then show us this data.
So, as you can see from this simple example, whatever you type on your keyboard can also go into the RAM – even if it’s your password or any kind of secure site you are surfing, your data is there on the RAM. It doesn’t matter what program you run. If you type using the keyboard everything will load on the RAM and can be extracted. This is called the memory dump.
LiME provides us with many other powerful capabilities. Right now, we are capturing the data directly from the system where we perform the actions. But we can also run LiME on the system and it can capture the data in real-time and send the data over the network to another computer.
What does this mean? Think of it this way: for example, somebody opens a website and they’re typing something in real-time. This entire message is being transmitted in real-time to another computer.
We’re not talking about key loggers, we are just talking about the RAM. Whatever is happening when any program is running, the database is storing some data. Programs are reading data from other parts of the hard disk. And whatever is happening on the RAM can be captured in real-time by the system and sent over the network to other computers.
Conclusion
We’ve finally come to the end of this article. I hope you’ve enjoyed it and have learned something new.
I’m always open to suggestions and discussions on LinkedIn. Hit me up with direct messages.
If you’ve enjoyed my writing and want to keep me motivated, consider leaving starts on GitHub and endorse me for relevant skills on LinkedIn.
Till the next one, stay safe and keep learning.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
По большей части ОЗУ бывает двух размеров: DIMM (Dual In-Line Memory Module), который используется в настольных ПК и серверах, и SO-DIMM (Small Outline DIMM), который используется в ноутбуках и других компьютерах малого форм-фактора. ,
Хотя оба форм-фактора ОЗУ используют одну и ту же технологию и работают одинаково, вы не можете смешивать их. Вы не можете просто вставить DIMM-флешку в слот SO-DIMM, и наоборот (контакты и слоты не совпадают!).
Когда вы покупаете RAM, первое, что нужно понять, это ее форм-фактор. Ничто не имеет значения, если палка не подходит!
Что означает ГДР?
Оперативная память, используемая на вашем компьютере, работает с использованием двойной скорости передачи данных (DDR). Оперативная память DDR означает, что две передачи происходят за такт. Новые типы ОЗУ являются обновленными версиями той же технологии, поэтому модули ОЗУ имеют метки DDR, DDR2, DDR3 и т. Д.
Хотя все поколения RAM имеют одинаковый физический размер и форму, они по-прежнему несовместимы . Вы не можете использовать оперативную память DDR3 в материнской плате, которая поддерживает только DDR2. Аналогично, DDR3 не подходит для слота DDR4. Чтобы избежать путаницы, каждое поколение ОЗУ имеет вырез в контактах в разных местах. Это означает, что вы не можете случайно перепутать ваши модули оперативной памяти или повредить материнскую плату, даже если вы покупаете неправильный тип.

DDR2
DDR2 — это самый старый вид оперативной памяти, с которым вы можете столкнуться сегодня. Он имеет 240 контактов (200 для SO-DIMM). DDR2 был хорошо и действительно заменен, но вы все равно можете купить его в ограниченном количестве, чтобы обновить старые машины. В противном случае DDR2 устареет.
DDR3
DDR3 был выпущен еще в 2007 году. Хотя он был официально заменен DDR4 в 2014 году, вы все равно найдете множество систем, использующих более старый стандарт RAM. Почему? Потому что только в 2016 году (два года после запуска DDR4) системы с поддержкой DDR4 действительно набирали обороты. Кроме того, оперативная память DDR3 охватывает огромный диапазон процессоров, начиная от сокета Intel LGA3636 и заканчивая LGA1151, а также AMD AM3 / AM3 + и FM1 / 2/2 +. (Для Intel это от введения линейки Intel Core i7 в 2008 году до 7- го поколения Kaby Lake!)
Оперативная память DDR3 имеет такое же количество контактов, что и DDR2. Тем не менее, он работает с более низким напряжением и имеет более высокие тайминги (больше на таймингах оперативной памяти в данный момент), поэтому не совместимы. Кроме того, модули DDR3 SO-DIMM имеют 204 контакта по сравнению с 200 контактами DDR2.
DDR4
DDR4 появился на рынке в 2014 году, но еще не полностью контролировал рынок оперативной памяти. Длительный период исключительно высоких цен на оперативную память приостановил модернизацию многих пользователей. Но по мере снижения цен все больше людей переключаются, тем более что последние поколения процессоров AMD и Intel используют исключительно оперативную память DDR4. Это означает, что если вы хотите перейти на более мощный процессор, вам нужна новая материнская плата и новая оперативная память.
DDR4 еще больше понижает напряжение ОЗУ, с 1,5 В до 1,2 В, увеличивая число контактов до 288.
DDR5
DDR5 должен выйти на потребительские рынки в 2019 году. Но учитывая, сколько времени обычно занимает распространение нового поколения RAM, ожидайте услышать об этом больше в 2020 году. Производитель RAM, SK Hynix, ожидает, что DDR5 будет занимать 25% рынка в 2020 г. и 44% в 2021 г.
DDR5 продолжит дизайн с 288-контактным разъемом, хотя напряжение ОЗУ упадет до 1,1 В. Ожидается, что производительность оперативной памяти DDR5 удвоит самый быстрый стандарт предыдущего поколения DDR4. Например, SK Hynix раскрыл технические подробности модуля оперативной памяти DDR5-6400, максимально быстрый из всех возможных по стандарту DDR5.
Но, как и с любым новым компьютерным оборудованием, при запуске ожидайте чрезвычайно высокую цену. Кроме того, если вы подумываете о покупке новой материнской платы , не сосредотачивайтесь на DDR5 . Он пока недоступен, и, несмотря на то, что говорит SK Hynix, Intel и AMD потребуется некоторое время, чтобы подготовиться
RAM Jargon: скорость, задержка, время и многое другое
Вы обернулись вокруг поколения SDRAM, DIMM и DDR. Но как насчет других длинных цепочек чисел в модели RAM? Что они имеют в виду? В чем измеряется ОЗУ? А что насчет ECC и Swap? Вот другие термины спецификации RAM, которые вы должны знать.
Тактовая частота, передача, пропускная способность
Возможно, вы видели ОЗУ, на которую ссылаются два набора чисел, например, DDR3-1600 и PC3-12800. Это и ссылка, и ссылка на генерацию оперативной памяти и ее скорость передачи . Число после DDR / PC и перед дефисом относится к поколению: DDR2 — это PC2, DDR3 — это PC3, DDR4 — это PC4.
Число, соединенное после DDR, относится к числу мегатрансферов в секунду (МТ / с). Например, оперативная память DDR3-1600 работает на скорости 1600 МТ / с. ОЗУ DDR5-6400, о котором говорилось выше, будет работать со скоростью 6400 МТ / с — намного быстрее! Число в паре после ПК относится к теоретической пропускной способности в мегабайтах в секунду. Например, PC3-12800 работает со скоростью 12 800 МБ / с.
Разгон ОЗУ возможен так же, как разгон процессора или видеокарты. Разгон увеличивает пропускную способность оперативной памяти. Производители иногда продают предварительно разогнанную оперативную память, но вы можете разогнать ее самостоятельно. Просто убедитесь, что ваша материнская плата поддерживает более высокую тактовую частоту RAM!
Вы можете быть удивлены, можете ли вы смешивать модули оперативной памяти с разными тактовыми частотами. Ответ в том, что да, вы можете, но все они будут работать на тактовой частоте самого медленного модуля. Если вы хотите использовать более быструю оперативную память, не смешивайте ее со старыми, более медленными модулями. Теоретически вы можете смешивать бренды RAM, но это не рекомендуется. У вас больше шансов встретить синий экран смерти или других случайных сбоев, когда вы смешиваете марки RAM или разные тактовые частоты RAM.
Сроки и задержка
Иногда вы увидите модули оперативной памяти с рядом цифр, например, 9-10-9-27. Эти цифры называются таймингами . Синхронизация ОЗУ — это измерение производительности модуля ОЗУ в наносекундах. Чем ниже цифры, тем быстрее ОЗУ реагирует на запросы.
Первое число (в примере 9) — это задержка CAS. Задержка CAS относится к числу тактовых циклов, необходимых для того, чтобы данные, запрошенные контроллером памяти, стали доступными для вывода данных.
Вы можете заметить, что DDR3 RAM обычно имеет более высокие тактовые номера, чем DDR2, а DDR4 обычно имеет более высокие тактовые номера, чем DDR3. Тем не менее, DDR4 быстрее, чем DDR3, который быстрее, чем DDR2. Странно, правда?

Мы можем объяснить это, используя DDR3 и DDR4 в качестве примеров.
Минимальная частота работы ОЗУ DDR3 составляет 533 МГц, что означает тактовую частоту 1/533000000 или 1,87 нс. При задержке CAS в 7 циклов общая задержка составляет 1,87 x 7 = 13,09 нс. («Нс» означает наносекунды.)
Принимая во внимание, что самая низкая скорость ОЗУ DDR4 составляет 800 МГц, что означает тактовую частоту 1/800000000, или 1,25 нс. Даже если он имеет более высокий CAS из 9 циклов, общая задержка составляет 1,25 x 9 = 11,25 нс. Вот почему это быстрее!
Для большинства людей пропускная способность всегда превосходит тактовую частоту и задержку . Вы получите гораздо больше преимуществ от 16 ГБ ОЗУ DDR4-1600, чем от 8 ГБ ОЗУ DDR4-2400. В большинстве случаев время и задержка являются последними пунктами рассмотрения.
ECC
ОЗУ с исправлением ошибок (ECC) — это особый тип модуля памяти, который предназначен для обнаружения и исправления повреждения данных. ECC ram используется на серверах, где ошибки в критически важных данных могут быть катастрофическими. Например, личная или финансовая информация хранится в оперативной памяти при манипулировании связанной базой данных.
Бытовые материнские платы и процессоры обычно не поддерживают ECC-совместимую оперативную память. Если вы не создаете сервер, который специально требует ОЗУ ECC, вы должны держаться подальше от него.
Сколько оперативной памяти вам нужно?
Давно прошли те времена, когда «640K должно хватить на всех». В мире, где смартфоны регулярно поставляются с 4 ГБ ОЗУ или более, а браузеры, такие как Google Chrome, играют быстро и свободно со своим распределением памяти, экономность ОЗУ — вещь мимо. Средний объем установленной оперативной памяти также увеличивается на всех типах оборудования.

Для большинства людей 4 ГБ — это минимальный объем оперативной памяти, необходимый для компьютера общего пользования. Операционные системы тоже имеют разные спецификации. Например, вы можете запустить Windows 10 только на 1 ГБ ОЗУ, но ваш пользовательский опыт будет вялым. И наоборот, многочисленные дистрибутивы Linux работают очень хорошо с меньшими объемами оперативной памяти
Если вы обнаружите, что одновременно открыты шесть документов Word, не можете заставить себя закрыть эти 60 вкладок в Google Chrome, возможно, вам понадобится как минимум 8 ГБ ОЗУ. То же самое происходит, если вы хотите использовать виртуальную машину.
16 ГБ ОЗУ должно превышать потребности большинства. Но если вы продолжите работу утилит в фоновом режиме, с множеством вкладок браузера и всего остального, вы по достоинству оцените дополнительную емкость ОЗУ. Очень немногие люди нуждаются в 32 ГБ ОЗУ, но, как говорится, чем больше, тем больше.
Обновление ОЗУ, безусловно, является одним из самых простых способов мгновенного повышения производительности. максимально повысить производительность
Понимание всего о оперативной памяти
Теперь вы знаете разницу между оперативной памятью DDR2, DDR3 и DDR4. Вы можете сказать DIMM от SO-DIMM, и вы знаете, как определить RAM с более высокими скоростями передачи и более высокой пропускной способностью. На этом этапе вы, по сути, являетесь экспертом в области ОЗУ, поэтому в следующий раз вы не будете испытывать перегрузку, пытаясь купить больше ОЗУ или совершенно новую систему.
Действительно, если у вас правильный форм-фактор и соответствующее поколение ОЗУ, вы не ошибетесь. Время и латентность играют свою роль, но способность — король. И если есть сомнения, больше ОЗУ лучше, чем быстрее ОЗУ важнее
Запоминающее
устройство (ЗУ)
– комплекс технических средств,
реализующих функцию памяти.
Назначение ЗУ:
-
ЗУ необходимы для
размещения на них команд и данных; -
Они обеспечивают
центральному процессору доступ к
программам и информации.
Персональные
компьютеры имеют три иерархических
уровня памяти:
-
Основная память;
-
Сверхоперативное
запоминающее устройство (КЭШ-память); -
Внешние запоминающие
устройства.
Основные
характеристики ЗУ:
-
емкость памяти,
измеряемая в битах либо в байтах; -
методы доступа
к данным; -
быстродействие
(время обращения к устройству); -
надежность
работы, характеризуемая зависимостью
от окружающей среды и колебаний
напряжения питания; -
стоимость единицы
памяти.
Две важнейших
характеристики (емкость памяти и ее
быстродействие) указанных типов памяти
приведены в табл. 9.1.
Такая важная
характеристика основной памяти и
кэш-памяти, как быстродействие измеряется
временем обращения (tобр)
к ним, а
быстродействие внешних запоминающих
устройств двумя параметрами: временем
доступа (tдост)
и скоростью
считывания (Vсчит):
tобр
– сумма
времени поиска, считывания и записи
информации (в литературе это время часто
называют временем доступа, что не совсем
строго);
tдост
– время
поиска информации на носителе;
Vсчит
– скорость
считывания смежных байтов информации
подряд (трансфер). Напомним общепринятые
сокращения: с — секунда, мс — миллисекунда,
мкс — микросекунда, нс — наносекунда; 1
с=10бмс=106мкс=109нс.
Основная память

|
ОЗУ |
ПЗУ |
|
Назначение: |
Назначение: |
Замечание:
Функциональные возможности ОЗУ шире,
чем у ПЗУ, но ПЗУ сохраняет информацию
при выключении питания (т.е. является
энергонезависимой памятью) и может
иметь более высокое быстродействие,
так как ограниченность функциональных
возможностей ПЗУ и его специализации
на чтении и хранении позволяют уменьшить
время считывания информации.
Оперативная память
Оперативное
запоминающее устройство
(ОЗУ
или RAM
– Random
Access
Memory)
предназначено для хранения переменной
информации. Оно допускает изменение
своего содержимого в ходе выполнения
процессором вычислительных операций
с данными и может работать в режимах
записи, чтения и хранения.
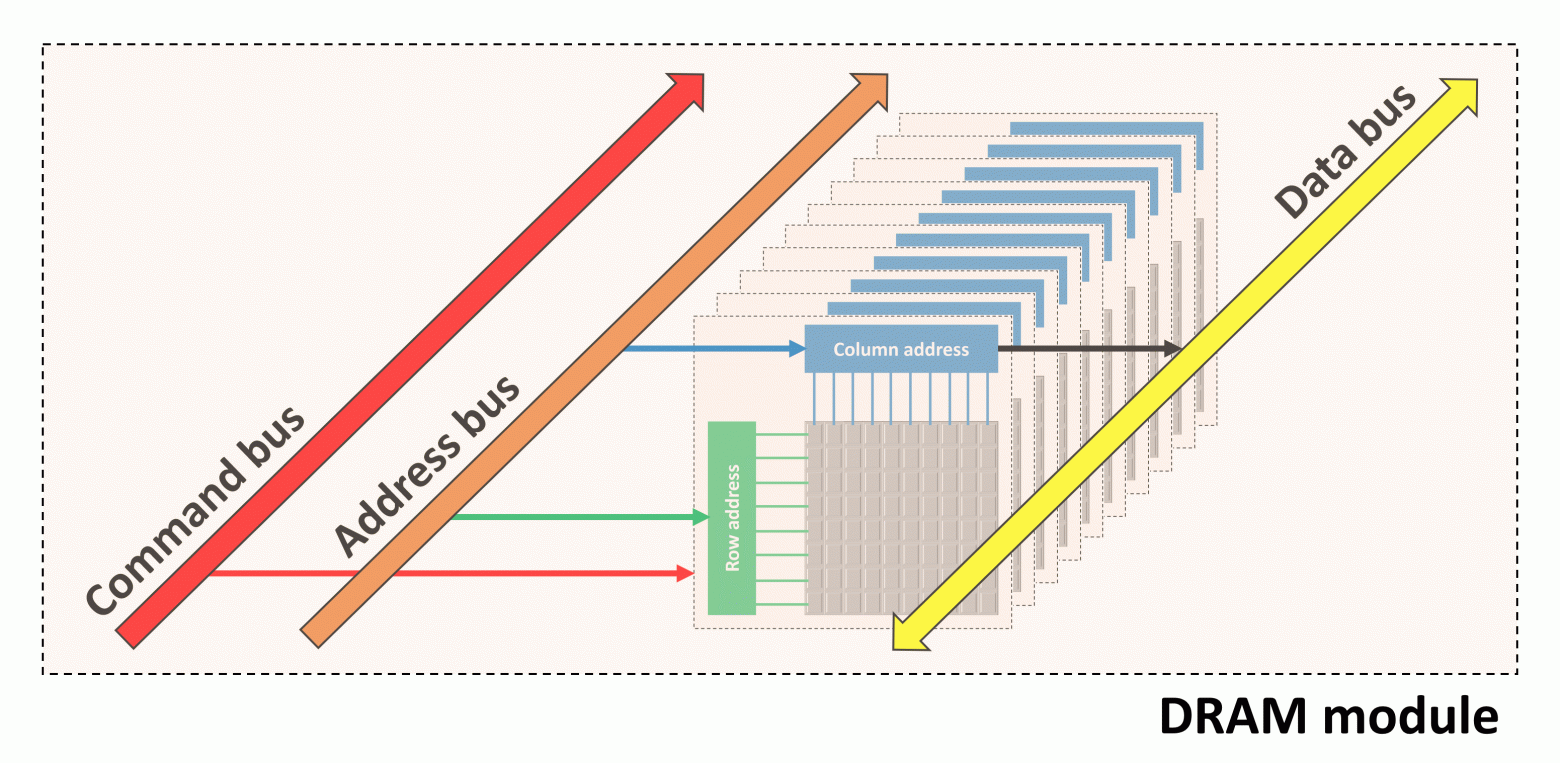
Структура
оперативной памяти:
Основная составная
часть микросхемы
представляет собой массив
элементов памяти (ЭП),
объединенных в матрицу накопителя.
Каждый элемент
памяти может хранить 1 бит информации
и имеет свой адрес. ЗУ, позволяющее
обращаться по адресу к любому ЭП в
произвольном порядке, называются
запоминающими устройствами с произвольным
доступом.
Упрощенная
структурная схема модуля оперативной
памяти при матричной его организации
представлена на рисунке 9.1.
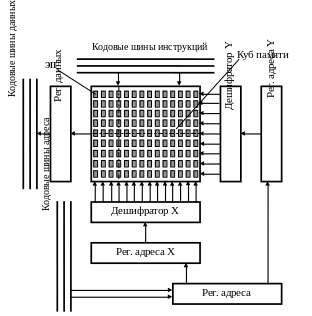
Рис. 9.1: Структурная
схема модуля основной памяти
Оперативная память
связана с остальным микропроцессорным
комплексом ЭВМ через системную шину.
По шине управления
передается сигнал, определяющий, какую
операцию необходимо выполнить.
По шине данных
передается информация, записываемая в
память или считываемая из нее.
По шине адреса
передается адрес участвующих в обмене
элементов памяти. Поскольку данные
передаются машинными словами, а один
ЭП может воспринять только один бит
информации, блок элементов памяти
состоит из п
матриц ЭП,
где п –
количество
разрядов в машинном слове. Максимальная
емкость памяти определяется количеством
линий в шине адреса системной магистрали
если количество линий обозначить через
т, то
емкость памяти (т.е. количество элементов
памяти имеющих уникальные адреса)
определяется как 2т.
Так, в IBM
PC
XT
шина адреса системной шины содержит 20
линий. Поэтому максимальный объем
основной памяти в этих машинах равен
220
= 1 Мбайт. В IBM
PC
AT
(с микропроцессором i80286) системная шина
содержит 24 линии, поэтому объем основной
памяти может быть увеличен до 16 Мбайт.
Начиная с МП i80386, шина адреса содержит
32
линии.
Максимальный объем основной памяти
увеличился до 232
= 4 Гбайта.
Принцип работы
оперативной памяти:
При матричной
организации памяти реализуется
координатный принцип адресации ЭП, т.е.
адрес делится на две части (две координаты)
– X
(номер строки)
и Y
(номер столбца).
На пересечении этих координат находится
элемент памяти, чью информацию нужно
прочитать или изменить.
При матричной
организации памяти реализуется
координатный принцип адресации ЭП, т.е.
адрес ячейки, поступающий в регистр
адреса по
кодовым шинам
адреса, делится
на две части (две координаты), поступающие
соответственно в Рег.
адреса X
и Рег.
адреса Y.
Из этих
регистров коды полуадресов поступают
в дешифраторы Дешифратор
X
и Дешифратор
Y,
которые
расшифровывают координаты – X
(номер строки)
и Y
(номер
столбца). Каждый из дешифраторов в
соответствии с полученным адресом (Х
или Y)
выбирает
одну из 1024 шин. По выбранным шинам
подаются сигналы записи/считывания в
ячейку памяти, находящуюся на пересечении
этих шин.
После того как
ячейка найдена, устройство управления
микропроцессора посылает по кодовой
шине инструкций сигнал считывания в
оперативную память. Данные из ячейки
считываются, предварительно записываются
в регистр
данных
оперативной памяти и уже из нее
пересылаются по шине
данных в
микропроцессор.
Разрядность шины
данных (8, 16, 32 или 64 бита) определяет
длину информационной единицы, которой
можно обменяться с ОЗУ за одно обращение.
Техническая
организация и особенности оперативной
памяти:
В современных ЭВМ
микросхемы памяти (ОЗУ, ПЗУ и кэш)
изготавливают из кремния по полупроводниковой
технологии с высокой степенью интеграции
элементов на кристалле (микросхемы
памяти относятся к так называемым
«регулярным» схемам, что позволяет
сделать установку элементов памяти в
кристалле (чипе) настолько плотной, что
размеры элементов памяти становятся
сопоставимыми с размерами отдельных
атомов).
Микросхемы
оперативной памяти строятся на
динамических элементах памяти, в качестве
которых выступают триггеры, сформированные
внутри кремниевого кристалла. Динамические
ЭП с течением времени записанную в них
информацию теряют, поэтому они нуждаются
в периодическом восстановлении записанной
в них информации – в регенерации.
Характеристики
оперативной памяти:
Основные
характеристиками ОЗУ:
объем
и быстродействие.
На производительность
ЭВМ влияют не только время
доступа, но
и такие параметры (связанные с ОЗУ), как
тактовая
частота и
разрядность
шины данных
системной магистрали. Если тактовая
частота недостаточно высока, то ОЗУ
простаивает в ожидании обращения. При
тактовой частоте, превышающей возможности
ОЗУ, в ожидании будет находиться системная
магистраль, через которую поступил
запрос в ОЗУ.
Интегральной
характеристикой производительности
ОЗУ с учетом частоты и разрядности
является пропускная
способность, которая
измеряется в мегабайтах в секунду. Для
оперативной памяти со временем доступа
60 – 70 нс и разрядностью шины данных 64
бита максимальная (теоретическая)
пропускная способность при тактовой
частоте системной шины 50 МГц составляет
400 Мбайт/с, при частоте 60 МГц – 480 Мбайт/с,
при 66 МГц – 528 Мбайт/с в режиме группового
обмена, реализуемом, например, при прямом
доступе к памяти.
Для группового
обмена
характерно (и это является еще одной
характеристикой ОЗУ), что при каждом
обращении к памяти для считывания
первого слова необходимо больше времени,
чем для последующих. Так, при использовании
стандартной динамической памяти FPM
(Fust
Page
Mode)
DRAM
на 60 – 70 нс каждое обращение к памяти в
групповом режиме описывается формулой
7-3-3-3, т.е. для обработки первого слова
необходимо 7 тактов (в течение 6 из которых
системная шина простаивает в ожидании),
а для обработки следующих трех слов –
по 3 такта, по 2 из которых системная шина
простаивает. Память типа EDO
(Extended
Data
Output)
DRAM
позволяет уменьшить количество циклов
ожидания (х-2-2-2, где х — количество тактов,
необходимое для обработки первого
слова). Память типа BEDO
(Burst
EDO)
DRAM
обеспечивает обмен по формуле х-1-1-1 для
первого обращения и 1-1-1-1 – для последующих.
Приведенные формулы характерны для
тактовых частот до 60 МГц. Синхронная
динамическая память (SDRAM
– Synchronous
DRAM)
способна обмениваться блоками данных
на рабочей тактовой частоте (внешняя
частота процессора) без циклов ожидания:
при времени доступа 10 нс – до 100 МГц, 12
нс – до 83 МГц и 15 нс – до 66 МГц.
Размещение
информации в оперативной памяти
Адресуемой
единицей информации основной памяти
IBM
PC
является байт. Это означает, что каждый
байт, записанный в оперативной памяти,
имеет уникальный номер (адрес).
Запись в оперативную
(и чтение из нее) может осуществляться
не только байтами, но и машинными словами.
При этом машинное слово при размещении
в памяти занимает несколько смежных
байтов. Каждый байт оперативной памяти
имеет свой адрес. Но машинное слово
характеризуется не всеми адресами
занятых байтов, а только одним – адресом
младшего байта машинного слова.
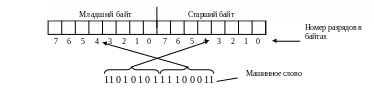
Рис. 9.2: Запись
машинного слова в оперативную память
При записи в
оперативную память единиц информации,
имеющих в своем составе больше одного
байта, адресом информационной единицы
является адрес самого младшего байта,
запись в оперативную память ведется
побайтно, начиная с самого младшего
байта, каждый последующий байт
располагается в ячейке, адрес которой
на 1 больше предыдущего.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Время на прочтение
14 мин
Количество просмотров 93K

У каждого компьютера есть ОЗУ, встроенное в процессор или находящееся на отдельной подключенной к системе плате — вычислительные устройства просто не смогли бы работать без оперативной памяти. ОЗУ — потрясающий образец прецизионного проектирования, однако несмотря на тонкость процессов изготовления, память ежегодно производится в огромных объёмах. В ней миллиарды транзисторов, но она потребляет только считанные ватты мощности. Учитывая большую важность памяти, стоит написать толковый анализ её анатомии.
Итак, давайте приготовимся к вскрытию, выкатим носилки и отправимся в анатомический театр. Настало время изучить все подробности каждой ячейки, из которых состоит современная память, и узнать, как она работает.
Зачем же ты, RAM-ео?
Процессорам требуется очень быстро получать доступ к данным и командам, чтобы программы выполнялись мгновенно. Кроме того, им нужно, чтобы при произвольных или неожиданных запросах не очень страдала скорость. Именно поэтому для компьютера так важно ОЗУ (RAM, сокращение от random-access memory — память с произвольным доступом).
Существует два основных типа RAM: статическая и динамическая, или сокращённо SRAM и DRAM.
Мы будем рассматривать только DRAM, потому что SRAM используется только внутри процессоров, таких как CPU или GPU. Так где же находится DRAM в наших компьютерах и как она работает?
Большинству людей знакома RAM, потому что несколько её планок находится рядом с CPU (центральным процессором, ЦП). Эту группу DRAM часто называют системной памятью, но лучше её называть памятью CPU, потому что она является основным накопителем рабочих данных и команд процессора.

Как видно на представленном изображении, DRAM находится на небольших платах, вставляемых в материнскую (системную) плату. Каждую плату обычно называют DIMM или UDIMM, что расшифровывается как dual inline memory module (двухсторонний модуль памяти) (U обозначает unbuffered (без буферизации)). Подробнее мы объясним это позже; пока только скажем, что это самая известная RAM любого компьютера.
Она не обязательно должна быть сверхбыстрой, но современным ПК для работы с большими приложениями и для обработки сотен процессов, выполняемых в фоновом режиме, требуется много памяти.
Ещё одним местом, где можно найти набор чипов памяти, обычно является графическая карта. Ей требуется сверхбыстрая DRAM, потому что при 3D-рендеринге выполняется огромное количество операций чтения и записи данных. Этот тип DRAM предназначен для несколько иного использования по сравнению с типом, применяемым в системной памяти.
Ниже вы видите GPU, окружённый двенадцатью небольшими пластинами — это чипы DRAM. Конкретно этот тип памяти называется GDDR5X, о нём мы поговорим позже.

Графическим картам не нужно столько же памяти, как CPU, но их объём всё равно достигает тысяч мегабайт.
Не каждому устройству в компьютере нужно так много: например, жёстким дискам достаточно небольшого количества RAM, в среднем по 256 МБ; они используются для группировки данных перед записью на диск.

На этих фотографиях мы видим платы HDD (слева) и SSD (справа), на которых отмечены чипы DRAM. Заметили, что чип всего один? 256 МБ сегодня не такой уж большой объём, поэтому вполне достаточно одного куска кремния.
Узнав, что каждый компонент или периферийное устройство, выполняющее обработку, требует RAM, вы сможете найти память во внутренностях любого ПК. На контроллерах SATA и PCI Express установлены небольшие чипы DRAM; у сетевых интерфейсов и звуковых карт они тоже есть, как и у принтеров со сканнерами.
Если память можно встретить везде, она может показаться немного скучной, но стоит вам погрузиться в её внутреннюю работу, то вся скука исчезнет!
Скальпель. Зажим. Электронный микроскоп.
У нас нет всевозможных инструментов, которые инженеры-электронщики используют для изучения своих полупроводниковых творений, поэтому мы не можем просто разобрать чип DRAM и продемонстрировать вам его внутренности. Однако такое оборудование есть у ребят из TechInsights, которые сделали этот снимок поверхности чипа:
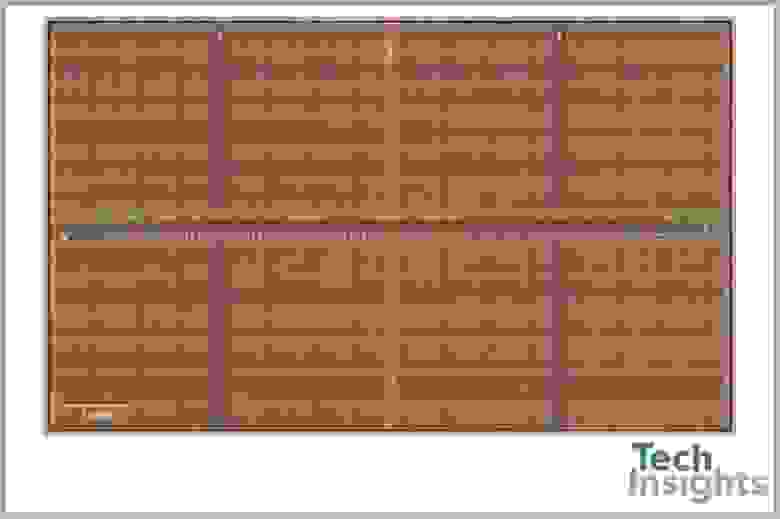
Если вы подумали, что это похоже на сельскохозяйственные поля, соединённые тропинками, то вы не так далеки от истины! Только вместо кукурузы или пшеницы поля DRAM в основном состоят из двух электронных компонентов:
- Переключателя, представленного MOSFET (МОП-транзистором)
- Накопителя, представляющего собой канавочный конденсатор.
Вместе они образуют так называемую ячейку памяти, каждая из которых содержит 1 бит данных. Очень приблизительная схема ячейки показана ниже (прощу прощения у специалистов по электронике!):
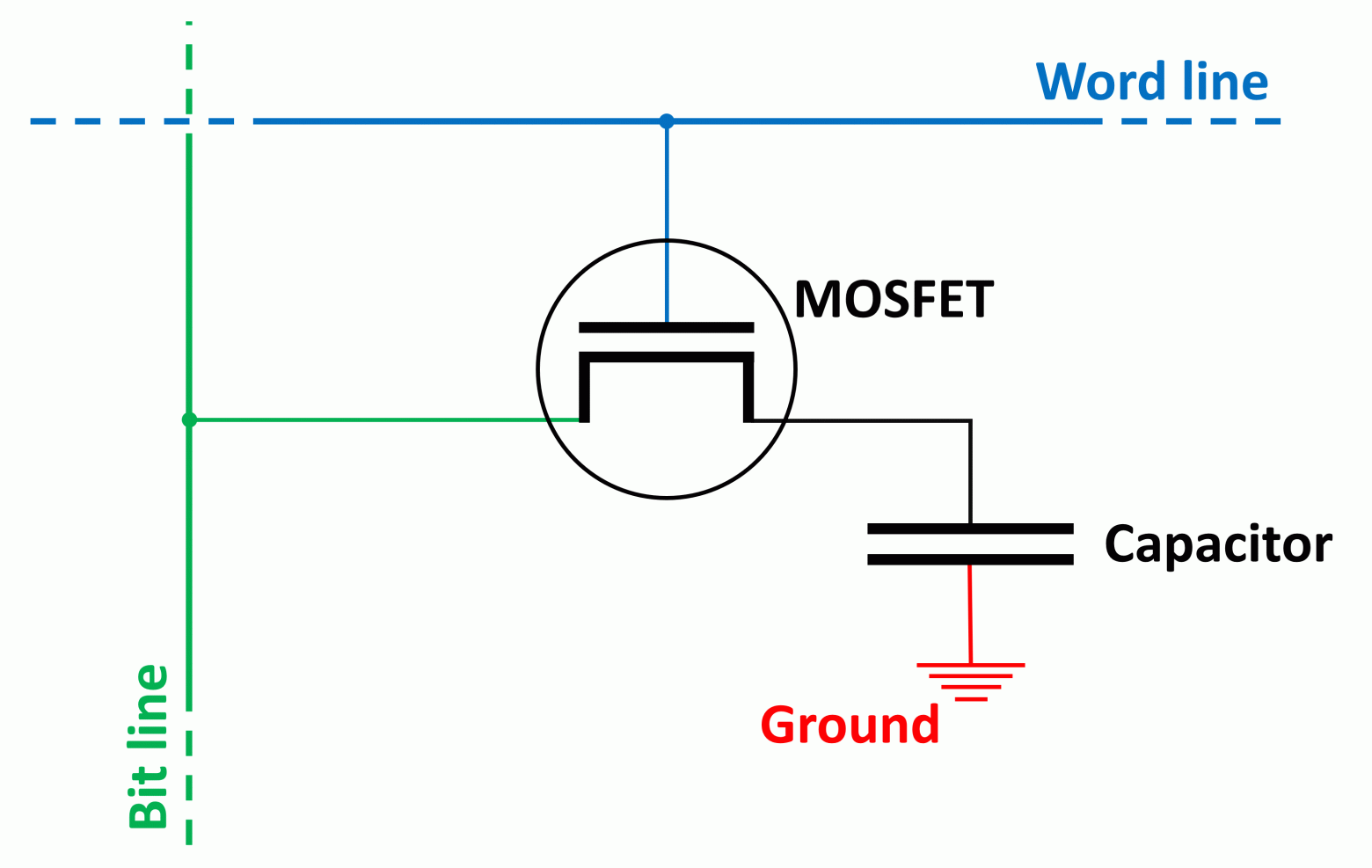
Синими и зелёными линиями обозначены соединения, подающие напряжение на МОП-транзистор и конденсатор. Они используются для считывания и записи данных в ячейку, и первой всегда срабатывает вертикальная (разрядная) линия.
Канавочный конденсатор, по сути, используется в качестве сосуда для заполнения электрическим зарядом — его пустое/заполненное состояние даёт нам 1 бит данных: 0 — пустой, 1 — полный. Несмотря на предпринимаемые инженерами усилия, конденсаторы не способны хранить этот заряд вечно и со временем он утекает.
Это означает, что каждую ячейку памяти нужно постоянно обновлять по 15-30 раз в секунду, хотя сам этот процесс довольно быстр: для обновления набора ячеек требуется всего несколько наносекунд. К сожалению, в чипе DRAM множество ячеек, и во время их обновления считывание и запись в них невозможна.
К каждой линии подключено несколько ячеек:

Строго говоря, эта схема неидеальна, потому что для каждого столбца ячеек используется две разрядные линии — если бы мы изобразили всё, то схема бы стала слишком неразборчивой.
Полная строка ячеек памяти называется страницей, а длина её зависит от типа и конфигурации DRAM. Чем длиннее страница, тем больше в ней бит, но и тем большая электрическая мощность нужна для её работы; короткие страницы потребляют меньше мощности, но и содержат меньший объём данных.
Однако нужно учитывать и ещё один важный фактор. При считывании и записи на чип DRAM первым этапом процесса является активация всей страницы. Строка битов (состоящая из нулей и единиц) хранится в буфере строки, который по сути является набором усилителей считывания и защёлок, а не дополнительной памятью. Затем активируется соответствующий столбец для извлечения данных из этого буфера.
Если страница слишком мала, то чтобы успеть за запросами данных, строки нужно активировать чаще; и наоборот — большая страница предоставляет больше данных, поэтому активировать её можно реже. И даже несмотря на то, что длинная строка требует большей мощности и потенциально может быть менее стабильной, лучше стремиться к получению максимально длинных страниц.

Если собрать вместе набор страниц, то мы получим один банк памяти DRAM. Как и в случае страниц, размер и расположение строк и столбцов ячеек играют важную роль в количестве хранимых данных, скорости работы памяти, энергопотреблении и так далее.
Например, схема может состоять из 4 096 строк и 4 096 столбцов, при этом полный объём одного банка будет равен 16 777 216 битам или 2 мегабайтам. Но не у всех чипов DRAM банки имеют квадратную структуру, потому что длинные страницы лучше, чем короткие. Например, схема из 16 384 строк и 1 024 столбцов даст нам те же 2 мегабайта памяти, но каждая страница будет содержать в четыре раза больше памяти, чем в квадратной схеме.
Все страницы в банке соединены с системой адресации строк (то же относится и к столбцам) и они контролируются сигналами управления и адресами для каждой строки/столбца. Чем больше строк и столбцов в банке, тем больше битов должно использоваться в адресе.
Для банка размером 4 096 x 4 096 для каждой системы адресации требуется 12 бит, а для банка 16 384 x 1 024 потребуется 14 бит на адреса строк и 10 бит на адреса столбцов. Стоит заметить, что обе системы имеют суммарный размер 24 бита.
Если бы чип DRAM мог предоставлять доступ к одной странице за раз, то это было бы не особо удобно, поэтому в них упаковано несколько банков ячеек памяти. В зависимости от общего размера, чип может иметь 4, 8 или даже 16 банков — чаще всего используется 8 банков.
Все эти банки имеют общие шины команд, адресов и данных, что упрощает структуру системы памяти. Пока один банк занят работой с одной командой, другие банки могут продолжать выполнение своих операций.
Весь чип, содержащий все банки и шины, упакован в защитную оболочку и припаян к плате. Она содержит электропроводники, подающие питание для работы DRAM и сигналов команд, адресов и данных.

На фотографии выше показан чип DRAM (иногда называемый модулем), изготовленный компанией Samsung. Другими ведущими производителями являются Toshiba, Micron, SK Hynix и Nanya. Samsung — крупнейший производитель, он имеет приблизительно 40% мирового рынка памяти.
Каждый изготовитель DRAM использует собственную систему кодирования характеристик памяти; на фотографии показан чип на 1 гигабит, содержащий 8 банков по 128 мегабита, выстроенных в 16 384 строки и 8 192 столбца.
Выше по рангу
Компании-изготовители памяти берут несколько чипов DRAM и устанавливают их на одну плату, называемую DIMM. Хотя D расшифровывается как dual (двойная), это не значит, что на ней два набора чипов. Под двойным подразумевается количество электрических контактов в нижней части платы; то есть для работы с модулями используются обе стороны платы.
Сами DIMM имеют разный размер и количество чипов:

На фотографии сверху показана стандартная DIMM для настольного ПК, а под ней находится так называемая SO-DIMM (small outline, «DIMM малого профиля»). Маленький модуль предназначен для ПК малого форм-фактора, например, ноутбуков и компактных настольных компьютеров. Из-за малого пространства уменьшается количество используемых чипов, изменяется скорость работы памяти, и так далее.
Существует три основных причины для использования нескольких чипов памяти на DIMM:
- Это увеличивает объём доступного хранилища
- В любой момент времени возможен доступ только к одному банку, поэтому благодаря работе остальных в фоновом режиме повышается производительность.
- Шина адреса в процессоре, обрабатывающая память, шире, чем шина DRAM.
Последнее очень важно, потому что в большинстве чипов DRAM используется только 8-битная шина данных. Однако CPU и GPU в этом от них отличаются: например, CPU AMD Ryzen 7 3800X имеет два встроенных 64-битных контроллера, а в Radeon RX 5700 XT встроено восемь 32-битных контроллеров.
То есть каждому DIMM, который устанавливается в компьютер с Ryzen, потребуется восемь модулей DRAM (8 чипов x 8 бит = 64 бита). Можно подумать, что графическая карта 5700 XT будет иметь 32 чипа памяти, но у неё их только 8. Что же это нам даёт?
В чипы памяти, предназначенные для графических карт, устанавливают больше банков, обычно 16 или 32, потому что для 3D-рендеринга необходим одновременный доступ к большому объёму данных.
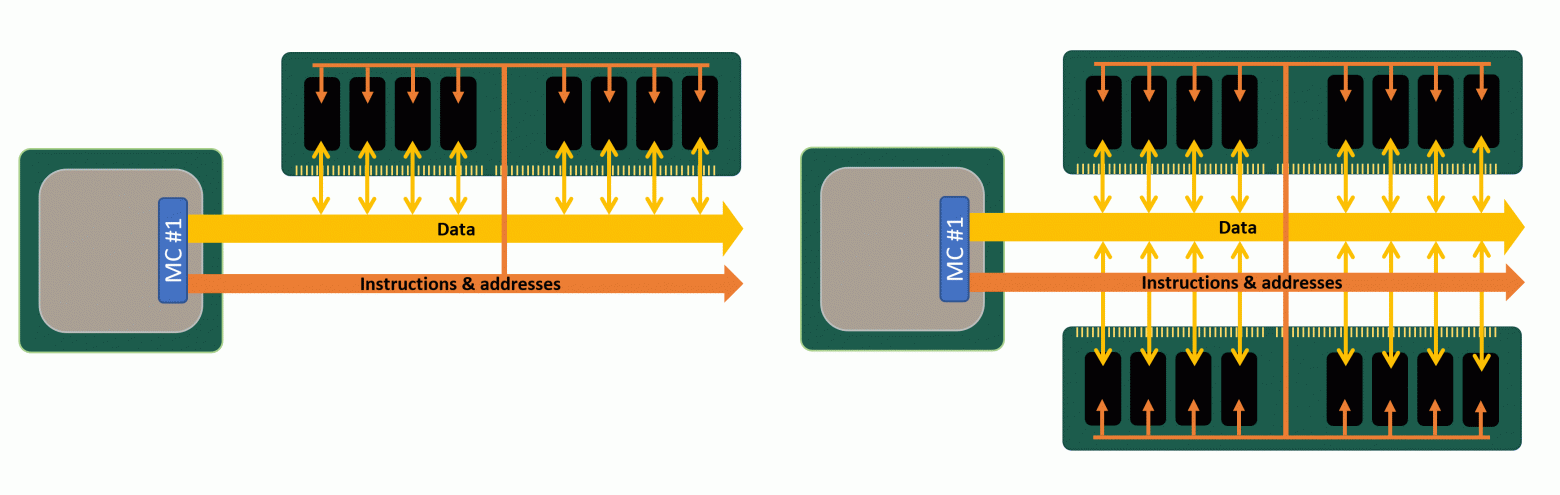
Один ранг и два ранга
Множество модулей памяти, «заполняющих» шину данных контроллера памяти, называется рангом, и хотя к контроллеру можно подключить больше одного ранга, за раз он может получать данные только от одного ранга (потому что ранги используют одну шину данных). Это не вызывает проблем, потому что пока один ранг занимается ответом на переданную ему команду, другому рангу можно передать новый набор команд.
Платы DIMM могут иметь несколько рангов и это особенно полезно, когда вам нужно огромное количество памяти, но на материнской плате мало разъёмов под RAM.
Так называемые схемы с двумя (dual) или четырьмя (quad) рангами потенциально могут обеспечить большую производительность, чем одноранговые, но увеличение количества рангов быстро повышает нагрузку на электрическую систему. Большинство настольных ПК способно справиться только с одним-двумя рангами на один контроллер. Если системе нужно больше рангов, то лучше использовать DIMM с буферизацией: такие платы имеют дополнительный чип, облегчающий нагрузку на систему благодаря хранению команд и данных в течение нескольких циклов, прежде чем передать их дальше.

Множество модулей памяти Nanya и один буферный чип — классическая серверная RAM
Но не все ранги имеют размер 64 бита — используемые в серверах и рабочих станциях DIMM часто размером 72 бита, то есть на них есть дополнительный модуль DRAM. Этот дополнительный чип не обеспечивает повышение объёма или производительности; он используется для проверки и устранения ошибок (error checking and correcting, ECC).
Вы ведь помните, что всем процессорам для работы нужна память? В случае ECC RAM небольшому устройству, выполняющему работу, предоставлен собственный модуль.
Шина данных в такой памяти всё равно имеют ширину всего 64 бита, но надёжность хранения данных значительно повышается. Использование буферов и ECC только незначительно влияет на общую производительность, зато сильно повышает стоимость.
Жажда скорости
У всех DRAM есть центральный тактовый сигнал ввода-вывода (I/O, input/output) — напряжение, постоянно переключающееся между двумя уровнями; он используется для упорядочивания всего, что выполняется в чипе и шинах памяти.
Если бы мы вернулись назад в 1993 год, то смогли бы приобрести память типа SDRAM (synchronous, синхронная DRAM), которая упорядочивала все процессы с помощью периода переключения тактового сигнала из низкого в высокое состояние. Так как это происходит очень быстро, такая система обеспечивает очень точный способ определения времени выполнения событий. В те времена SDRAM имела тактовые сигналы ввода-вывода, обычно работавшие с частотой от 66 до 133 МГц, и за каждый такт сигнала в DRAM можно было передать одну команду. В свою очередь, чип за тот же промежуток времени мог передать 8 бит данных.
Быстрое развитие SDRAM, ведущей силой которого был Samsung, привело к созданию в 1998 году её нового типа. В нём передача данных синхронизировалась по повышению и падению напряжения тактового сигнала, то есть за каждый такт данные можно было дважды передать в DRAM и обратно.
Как же называлась эта восхитительная новая технология? Double data rate synchronous dynamic random access memory (синхронная динамическая память с произвольным доступом и удвоенной скоростью передачи данных). Обычно её просто называют DDR-SDRAM или для краткости DDR.
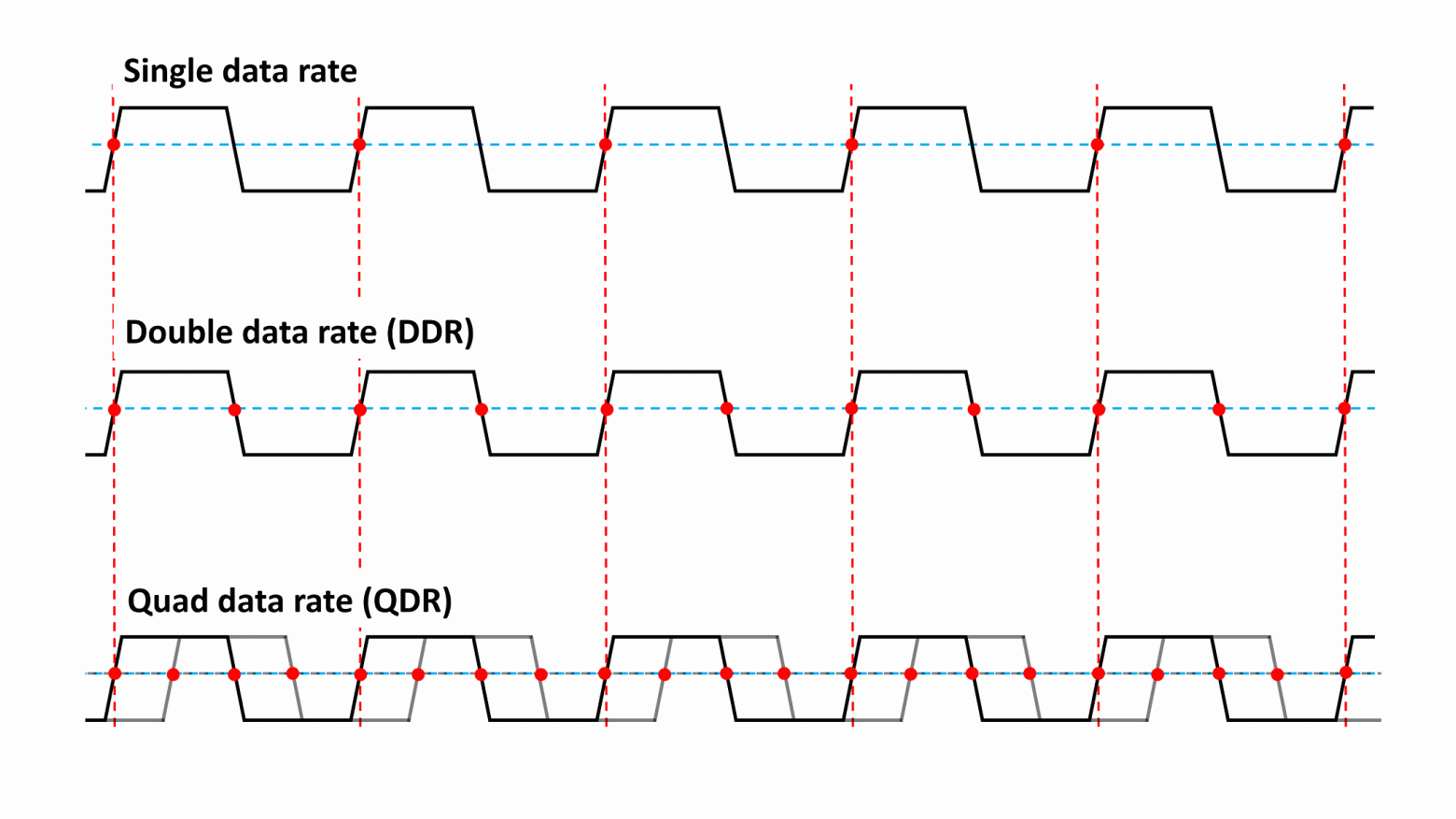
Память DDR быстро стала стандартом (из-за чего первоначальную версию SDRAM переименовали в single data rate SDRAM, SDR-DRAM) и в течение последующих 20 лет оставалась неотъемлемой частью всех компьютерных систем.
Прогресс технологий позволил усовершенствовать эту память, благодаря чему в 2003 году появилась DDR2, в 2007 году — DDR3, а в 2012 году — DDR4. Каждая новая версия обеспечивала повышение производительности благодаря ускорению тактового сигнала ввода-вывода, улучшению систем сигналов и снижению энергопотребления.
DDR2 внесла изменение, которое мы используем и сегодня: генератор тактовых сигналов ввода-вывода превратился в отдельную систему, время работы которой задавалось отдельным набором синхронизирующих сигналов, благодаря чему она стала в два раза быстрее. Это аналогично тому, как CPU используют для упорядочивания работы тактовый сигнал 100 МГц, хотя внутренние синхронизирующие сигналы работают в 30-40 раз быстрее.
DDR3 и DDR4 сделали шаг вперёд, увеличив скорость тактовых сигналов ввода-вывода в четыре раза, но во всех этих типах памяти шина данных для передачи/получения информации по-прежнему использовала только повышение и падение уровня сигнала ввода-вывода (т.е. удвоенную частоту передачи данных).
Сами чипы памяти не работают на огромных скоростях — на самом деле, они шевелятся довольно медленно. Частота передачи данных (измеряемая в миллионах передач в секунду — millions of transfers per second, MT/s) в современных DRAM настолько высока благодаря использованию в каждом чипе нескольких банков; если бы на каждый модуль приходился только один банк, всё работало бы чрезвычайно медленно.
Каждая новая версия DRAM не обладает обратной совместимостью, то есть используемые для каждого типа DIMM имеют разные количества электрических контактов, разъёмы и вырезы, чтобы пользователь не мог вставить память DDR4 в разъём DDR-SDRAM.

Сверху вниз: DDR-SDRAM, DDR2, DDR3, DDR4
DRAM для графических плат изначально называлась SGRAM (synchronous graphics, синхронная графическая RAM). Этот тип RAM тоже подвергался усовершенствованиям, и сегодня его для понятности называют GDDR. Сейчас мы достигли версии 6, а для передачи данных используется система с учетверённой частотой, т.е. за тактовый цикл происходит 4 передачи.
Кроме более высокой частоты передачи, графическая DRAM обеспечивает дополнительные функции для ускорения передачи, например, возможность одновременного открытия двух страниц одного банка, работающие в DDR шины команд и адресов, а также чипы памяти с гораздо большими скоростями тактовых сигналов.
Какой же минус у всех этих продвинутых технологий? Стоимость и тепловыделение.
Один модуль GDDR6 примерно вдвое дороже аналогичного чипа DDR4, к тому же при полной скорости он становится довольно горячим — именно поэтому графическим картам с большим количеством сверхбыстрой RAM требуется активное охлаждение для защиты от перегрева чипов.
Скорость битов
Производительность DRAM обычно измеряется в количестве битов данных, передаваемых за секунду. Ранее в этой статье мы говорили, что используемая в качестве системной памяти DDR4 имеет чипы с 8-битной шириной шины, то есть каждый модуль может передавать до 8 бит за тактовый цикл.
То есть если частота передачи данных равна 3200 MT/s, то пиковый результат равен 3200 x 8 = 25 600 Мбит в секунду или чуть больше 3 ГБ/с. Так как большинство DIMM имеет 8 чипов, потенциально можно получить 25 ГБ/с. Для GDDR6 с 8 модулями этот результат был бы равен 440 ГБ/с!
Обычно это значение называют полосой пропускания (bandwidth) памяти; оно является важным фактором, влияющим на производительность RAM. Однако это теоретическая величина, потому что все операции внутри чипа DRAM не происходят одновременно.
Чтобы разобраться в этом, давайте взглянем на показанное ниже изображение. Это очень упрощённое (и нереалистичное) представление того, что происходит, когда данные запрашиваются из памяти.
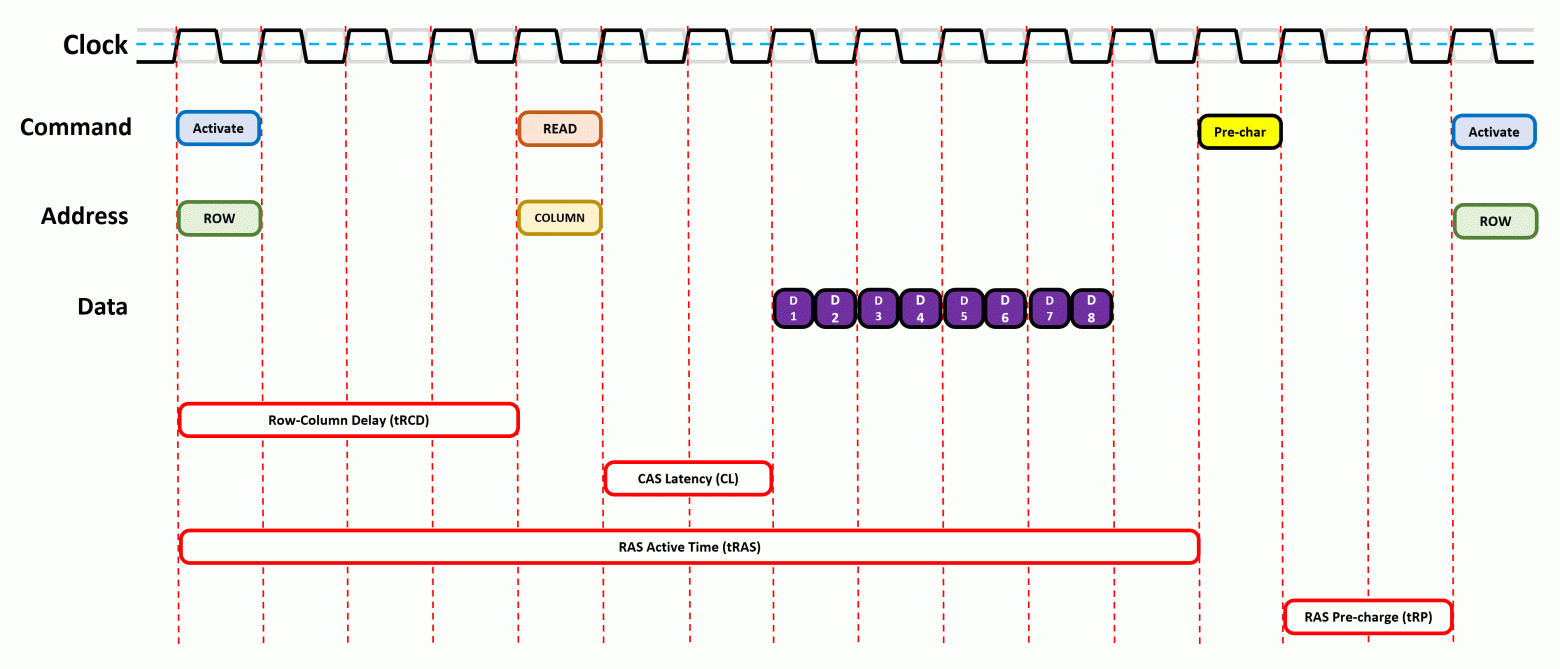
На первом этапе активируется страница DRAM, в которой содержатся требуемые данные. Для этого памяти сначала сообщается, какой требуется ранг, затем соответствующий модуль, а затем конкретный банк.
Чипу передаётся местоположение страницы данных (адрес строки), и он отвечает на это передачей целой страницы. На всё это требуется время и, что более важно, время нужно и для полной активации строки, чтобы гарантировать полную блокировку строки битов перед выполнением доступа к ней.
Затем определяется соответствующий столбец и извлекается единственный бит информации. Все типы DRAM передают данные пакетами, упаковывая информацию в единый блок, и пакет в современной памяти почти всегда равен 8 битам. То есть даже если за один тактовый цикл извлекается один бит, эти данные нельзя передать, пока из других банков не будет получено ещё 7 битов.
А если следующий требуемый бит данных находится на другой странице, то перед активацией следующей необходимо закрыть текущую открытую страницу (это процесс называется pre-charging). Всё это, разумеется, требует больше времени.
Все эти различные периоды между временем отправки команды и выполнением требуемого действия называются таймингами памяти или задержками. Чем ниже значение, тем выше общая производительность, ведь мы тратим меньше времени на ожидание завершения операций.
Некоторые из этих задержек имеют знакомые фанатам компьютеров названия:
Существует ещё много других таймингов и все их нужно тщательно настраивать, чтобы DRAM работала стабильно и не искажала данные, имея при этом оптимальную производительность. Как можно увидеть из таблицы, схема, демонстрирующая циклы в действии, должна быть намного шире!
Хотя при выполнении процессов часто приходится ждать, команды можно помещать в очереди и передавать, даже если память занята чем-то другим. Именно поэтому можно увидеть много модулей RAM там, где нам нужна производительность (системная память CPU и чипы на графических картах), и гораздо меньше модулей там, где они не так важны (в жёстких дисках).
Тайминги памяти можно настраивать — они не заданы жёстко в самой DRAM, потому что все команды поступают из контроллера памяти в процессоре, который использует эту память. Производители тестируют каждый изготавливаемый чип и те из них, которые соответствуют определённым скоростям при заданном наборе таймингов, группируются вместе и устанавливаются в DIMM. Затем тайминги сохраняются в небольшой чип, располагаемый на плате.

Даже памяти нужна память. Красным указано ПЗУ (read-only memory, ROM), в котором содержится информация SPD.
Процесс доступа к этой информации и её использования называется serial presence detect (SPD). Это отраслевой стандарт, позволяющий BIOS материнской платы узнать, на какие тайминги должны быть настроены все процессы.
Многие материнские платы позволяют пользователям изменять эти тайминги самостоятельно или для улучшения производительности, или для повышения стабильности платформы, но многие модули DRAM также поддерживают стандарт Extreme Memory Profile (XMP) компании Intel. Это просто дополнительная информация, хранящаяся в памяти SPD, которая сообщает BIOS: «Я могу работать с вот с такими нестандартными таймингами». Поэтому вместо самостоятельной возни с параметрами пользователь может настроить их одним нажатием мыши.
Спасибо за службу, RAM!
В отличие от других уроков анатомии, этот оказался не таким уж грязным — DIMM сложно разобрать и для изучения модулей нужны специализированные инструменты. Но внутри них таятся потрясающие подробности.
Возьмите в руку планку памяти DDR4-SDRAM на 8 ГБ из любого нового ПК: в ней упаковано почти 70 миллиардов конденсаторов и такое же количество транзисторов. Каждый из них хранит крошечную долю электрического заряда, а доступ к ним можно получить за считанные наносекунды.
Даже при повседневном использовании она может выполнять бесчисленное количество команд, и большинство из плат способны без малейших проблем работать многие годы. И всё это меньше чем за 30 долларов? Это просто завораживает.
DRAM продолжает совершенствоваться — уже скоро появится DDR5, каждый модуль которой обещает достичь уровня полосы пропускания, с трудом достижимый для двух полных DIMM типа DDR4. Сразу после появления она будет очень дорогой, но для серверов и профессиональных рабочих станций такой скачок скорости окажется очень полезным.
См. также:
- «Обновленные SSD для ЦОД: большие объёмы для больших ребят»
- «Внешние накопители данных: от времен IBM 1311 до наших дней. Часть 1»
- «Внешние накопители данных: от времен IBM 1311 до наших дней. Часть 2»
Введение
Мы продолжаем публикацию цикла «руководств пользователя», посвященных теоретическому и практическому рассмотрению различных компонентов современного ПК, начало которому положил материал «Современные десктопные процессоры архитектуры x86: общие принципы работы (x86 CPU FAQ 1.0)». В настоящем руководстве мы рассмотрим основные современные виды оперативной памяти, применяемой в десктопных системах (оперативную память, применяемую в серверах и ноутбуках, оставим за его рамками). Под ними будем подразумевать память класса SDRAM — SDR (Single Data Rate — память с одинарной скоростью передачи данных), DDR (Double Data Rate — память с удвоенной скоростью передачи данных) и DDR2 (память DDR второго поколения). Возможно, SDRAM «как таковая» (в ее первоначальном варианте SDR SDRAM) на сегодня уже не является столь актуальным видом памяти, тем не менее, все три перечисленных вида принадлежат одному и тому же классу и базируются примерно на одних и тех же принципах функционирования, которые мы и рассмотрим прямо сейчас.Содержание
- Часть 1. Теоретические основы современной оперативной памяти
- SDRAM: Определение
- Микросхемы SDRAM: Физическая организация и принцип работы
- Микросхемы SDRAM: Логическая организация
- Модули SDRAM: Организация
- Модули памяти: Микросхема SPD
- Тайминги памяти
- Схема доступа к данным микросхемы SDRAM
- Соотношения между таймингами
- Схемы таймингов
- Задержки командного интерфейса
- DDR/DDR2 SDRAM: Отличия от SDR SDRAM
Часть 1. Теоретические основы современной оперативной памяти
SDRAM: Определение
Аббревиатура SDRAM расшифровывается как Synchronous Dynamic Random Access Memory — синхронная динамическая память с произвольным доступом. Остановимся подробнее на каждом из этих определений. Под «синхронностью» обычно понимается строгая привязка управляющих сигналов и временных диаграмм функционирования памяти к частоте системной шины. Вообще говоря, в настоящее время изначальный смысл понятия синхронности становится несколько условным. Во-первых, частота шины памяти может отличаться от частоты системной шины (в качестве примера можно привести уже сравнительно давно существующий «асинхронный» режим работы памяти DDR SDRAM на платформах AMD K7 с чипсетами VIA KT333/400, в которых частоты системной шины процессора и шины памяти могут соотноситься как 133/166 или 166/200 МГц). Во-вторых, ныне существуют системы, в которых само понятие «системной шины» становится условным — речь идет о платформах класса AMD Athlon 64 с интегрированным в процессор контроллером памяти. Частота «системной шины» (под которой в данном случае понимается не шина HyperTransport для обмена данными с периферией, а непосредственно «шина» тактового генератора) в этих платформах является лишь опорной частотой, которую процессор умножает на заданный коэффициент для получения собственной частоты. При этом контроллер памяти всегда функционирует на той же частоте, что и сам процессор, а частота шины памяти задается целым делителем, который может не совпадать с первоначальным коэффициентом умножения частоты «системной шины». Так, например, режиму DDR-333 на процессоре AMD Athlon 64 3200+ будут соответствовать множитель частоты «системной шины» 10 (частота процессора и контроллера памяти 2000 МГц) и делитель частоты памяти 12 (частота шины памяти 166.7 МГц). Таким образом, под «синхронной» операцией SDRAM в настоящее время следует понимать строгую привязку временных интервалов отправки команд и данных по соответствующим интерфейсам устройства памяти к частоте шины памяти (проще говоря, все операции в ОЗУ совершаются строго по фронту/срезу синхросигнала интерфейса памяти). Так, отправка команд и чтение/запись данных может осуществляться на каждом такте шины памяти (по положительному перепаду — «фронту» синхросигнала; в случае памяти DDR/DDR2 передача данных происходит как по «фронту», так и по отрицательному перепаду — «срезу» синхросигнала), но не по произвольным временным интервалам (как это осуществлялось в асинхронной DRAM).
Понятие «динамической» памяти, DRAM, относится ко всем типам оперативной памяти, начиная с самой древней, «обычной» асинхронной динамической памяти и заканчивая современной DDR2. Этот термин вводится в противоположность понятия «статической» памяти (SRAM) и означает, что содержимое каждой ячейки памяти периодически необходимо обновлять (ввиду особенности ее конструкции, продиктованной экономическими соображениями). В то же время, статическая память, характеризующаяся более сложной и более дорогой конструкцией ячейки и применяемая в качестве кэш-памяти в процессорах (а ранее — и на материнских платах), свободна от циклов регенерации, т.к. в ее основе лежит не емкость (динамическая составляющая), а триггер (статическая составляющая).
Наконец, стоит также упомянуть о «памяти с произвольным доступом» — Random Access Memory, RAM. Традиционно, это понятие противопоставляется устройствам «памяти только на чтение» — Read-Only Memory, ROM. Тем не менее, противопоставление это не совсем верно, т.к. из него можно сделать вывод, что память типа ROM не является памятью с произвольным доступом. Это неверно, потому как доступ к устройствам ROM может осуществляться в произвольном, а не строго последовательном порядке. И на самом деле, наименование «RAM» изначально противопоставлялось ранним типам памяти, в которых операции чтения/записи могли осуществляться только в последовательном порядке. В связи с этим, более правильно назначение и принцип работы оперативной памяти отражает аббревиатура «RWM» (Read-Write Memory), которая, тем не менее, встречается намного реже. Заметим, что русскоязычным сокращениям RAM и ROM — ОЗУ (оперативное запоминающее устройство) и ПЗУ (постоянное запоминающее устройство), соответственно, подобная путаница не присуща.
Микросхемы SDRAM: Физическая организация и принцип работы
Общий принцип организации и функционирования микросхем динамической памяти (DRAM) практически един для всех ее типов — как первоначальной асинхронной, так и современной синхронной. Исключение составляют разве что экзотические варианты, тем не менее, существовавшие еще до появления SDRAM, вроде Direct Rambus DRAM (DRDRAM). Массив памяти DRAM можно рассматривать как матрицу (двумерный массив) элементов (строго говоря, это понятие относится к логическому уровню организации микросхемы памяти, рассмотренному в следующем разделе, но его необходимо ввести здесь для наглядности), каждый из которых содержит одну или несколько физических ячеек (в зависимости от конфигурации микросхемы), способных вмещать элементарную единицу информации — один бит данных. Ячейки представляют собой сочетание транзистора (ключа) и конденсатора (запоминающего элемента). Доступ к элементам матрицы осуществляется с помощью декодеров адреса строки и адреса столбца, которые управляются сигналами RAS# (сигнал выбора строки — Row Access Strobe) и CAS# (сигнал выбора столбца — Column Access Strobe).
Из соображений минимизации размера упаковки микросхемы, адреса строк и столбцов передаются по одним и тем же адресным линиям микросхемы — иными словами, говорят о мультиплексировании адресов строк и столбцов (упомянутые выше отличия в общих принципах функционирования микросхем DRDRAM от «обычных» синхронных/асинхронных DRAM проявляются, в частности, здесь — в этом типе микросхем памяти адреса строк и столбцов передаются по разным физическим интерфейсам). Так, например, 22-разрядный полный адрес ячейки может разделяться на два 11-разрядных адреса (строки и столбца), которые последовательно (через определенный интервал времени, см. раздел «Тайминги памяти») подаются на адресные линии микросхемы памяти. Одновременно со второй частью адреса (адреса столбца) по единому командно-адресному интерфейсу микросхемы SDRAM подается соответствующая команда (чтения или записи данных). Внутри микросхемы памяти адреса строки и столбца временно сохраняются в буферах (защелках) адреса строки и адреса столбца, соответственно.
Важно заметить, что с динамической матрицей памяти связан особый буфер статической природы, именуемый «усилителем уровня» (SenseAmp), размер которого равен размеру одной строки, необходимый для осуществления операций чтения и регенерации данных, содержащихся в ячейках памяти. Поскольку последние физически представляют собой конденсаторы, разряжающиеся при совершении каждой операции чтения, усилитель уровня обязан восстановить данные, хранящиеся в ячейке, после завершения цикла доступа (более подробно участие усилителя уровня в цикле чтения данных из микросхемы памяти рассмотрено ниже).
Кроме того, поскольку конденсаторы со временем теряют свой заряд (независимо от операций чтения), для предотвращения потери данных необходимо периодически обновлять содержимое ячеек. В современных типах памяти, которые поддерживают режимы автоматической регенерации (в «пробужденном» состоянии) и саморегенерации (в «спящем» состоянии), обычно это является задачей внутреннего контроллера регенерации, расположенного непосредственно в микросхеме памяти.
Схема обращения к ячейке памяти в самом общем случае может быть представлена следующим образом:
1. На адресные линии микросхемы памяти подается адрес строки. Наряду с этим подается сигнал RAS#, который помещает адрес в буфер (защелку) адреса строки.
2. После стабилизации сигнала RAS#, декодер адреса строки выбирает нужную строку, и ее содержимое перемещается в усилитель уровня (при этом логическое состояние строки массива инвертируется).
3. На адресные линии микросхемы памяти подается адрес столбца вместе с подачей сигнала CAS#, помещающего адрес в буфер (защелку) адреса столбца.
4. Поскольку сигнал CAS# также служит сигналом вывода данных, по мере его стабилизации усилитель уровня отправляет выбранные (соответствующие адресу столбца) данные в буфер вывода.
5. Сигналы CAS# и RAS# последовательно дезактивируются, что позволяет возобновить цикл доступа (по прошествии промежутка времени, в течение которого данные из усилителя уровня возвращаются обратно в массив ячеек строки, восстанавливая его прежнее логическое состояние).
Так выглядела реальная схема доступа к ячейке DRAM в самом первоначальном ее варианте, реализованном еще до появления первых реально используемых микросхем/модулей асинхронной памяти типа FPM (Fast Page Mode) DRAM. Тем не менее, нетрудно заметить, что эта схема является достаточно неоптимальной. Действительно, если нам требуется считать содержимое не одной, а сразу нескольких подряд расположенных ячеек, отличающихся только адресом столбца, но не адресом строки, то нет необходимости каждый раз подавать сигнал RAS# с одним и тем же адресом строки (т.е. выполнять шаги 1-2). Вместо этого, достаточно удерживать сигнал RAS# активным на протяжении промежутка времени, соответствующего, например, четырем последовательным циклам чтения (шаги 3-4, с последующей дезактивацией CAS#), после чего дезактивировать сигнал RAS#. Именно такая схема применялась в асинхронной памяти типа FPM DRAM и более поздней EDO (Enhanced Data Output) DRAM. Последняя отличалась опережающей подачей адреса следующего столбца, что позволяло достичь меньших задержек при операциях чтения.
В современных микросхемах SDRAM схема обращения к ячейкам памяти выглядит аналогично. Далее, в связи с обсуждением задержек при доступе в память (таймингов памяти), мы рассмотрим ее более подробно.
Микросхемы SDRAM: Логическая организация
А пока перейдем к рассмотрению организации микросхем памяти SDRAM на логическом уровне. Как уже было сказано выше, микросхема DRAM, фактически, представляет собой двумерный массив (матрицу) элементов, состоящих из одного или нескольких элементарных физических ячеек. Очевидно, что главной характеристикой этого массива является его емкость, выражаемая в количестве бит информации, которую он способен вместить. Часто можно встретить понятия «256-Мбит», «512-Мбит» микросхем памяти — речь здесь идет именно об этом параметре. Однако составить эту емкость можно разными способами — мы говорим сейчас не о количестве строк и столбцов, но о размерности, или «вместимости» индивидуального элемента. Последняя прямо связана с количеством линий данных, т.е. шириной внешней шины данных микросхемы памяти (но не обязательно с коэффициентом пропорциональности в единицу, что мы увидим ниже, при рассмотрении отличий памяти типа DDR и DDR2 SDRAM от «обычной» SDRAM). Ширина шины данных самых первых микросхем памяти составляла всего 1 бит, в настоящее же время наиболее часто встречаются 4-, 8- и 16- (реже — 32-) битные микросхемы памяти. Таким образом, микросхему памяти емкостью 512 Мбит можно составить, например, из 128М (134 217 728) 4-битных элементов, 64М (67 108 864) 8-битных элементов или 32М (33 554 432) 16-битных элементов — соответствующие конфигурации записываются как «128Mx4», «64Mx8» и «32Mx16». Первая из этих цифр именуется глубиной микросхемы памяти (безразмерная величина), вторая — шириной (выраженная в битах).
Существенная отличительная особенность микросхем SDRAM от микросхем более ранних типов DRAM заключается в разбиении массива данных на несколько логических банков (как минимум — 2, обычно — 4). Не следует путать это понятие с понятием «физического банка» (называемого также «ранком» (rank) памяти), определенным для модуля, но не микросхемы памяти — его мы рассмотрим далее. Сейчас лишь отметим, что внешняя шина данных каждого логического банка (в отличие от физического, который составляется из нескольких микросхем памяти для «заполнения» шины данных контроллера памяти) характеризуется той же разрядностью (шириной), что и разрядность (ширина) внешней шины данных микросхемы памяти в целом (x4, x8 или x16). Иными словами, логическое разделение массива микросхемы на банки осуществляется на уровне количества элементов в массиве, но не разрядности элементов. Таким образом, рассмотренные выше реальные примеры логической организации 512-Мбит микросхемы при ее «разбиении» на 4 банка могут быть записаны как 32Mx4x4 банка, 16Mx8x4 банка и 8Mx16x4 банка, соответственно. Тем не менее, намного чаще на маркировке микросхем памяти (либо ее расшифровке в технической документации) встречаются именно конфигурации «полной» емкости, без учета ее разделения на отдельные логические банки, тогда как подробное описание организации микросхемы (количество банков, строк и столбцов, ширину внешней шины данных банка) можно встретить лишь в подробной технической документации на данный вид микросхем SDRAM.
Разбиение массива памяти SDRAM на банки было введено, главным образом, из соображений производительности (точнее, минимизации системных задержек — т.е. задержек поступления данных в систему). В самом простом и пока достаточном изложении, можно сказать, что после осуществления любой операции со строкой памяти, после дезактивации сигнала RAS#, требуется определенное время для осуществления ее «подзарядки». И преимущество «многобанковых» микросхем SDRAM заключается в том, что можно обращаться к строке одного банка, пока строка другого банка находится на «подзарядке». Можно расположить данные в памяти и организовать к ним доступ таким образом, что далее будут запрашиваться данные из второго банка, уже «подзаряженного» и готового к работе. В этот момент вполне естественно «подзаряжать» первый банк, и так далее. Такая схема доступа к памяти называется «доступом с чередованием банков» (Bank Interleave).
Модули SDRAM: Организация
Основные параметры логической организации микросхем памяти — емкость, глубину и ширину, можно распространить и на модули памяти типа SDRAM. Понятие емкости (или объема) модуля очевидно — это максимальный объем информации, который данный модуль способен в себя вместить. Теоретически он может выражаться и в битах, однако общепринятой «потребительской» характеристикой модуля памяти является его объем (емкость), выраженный в байтах — точнее, учитывая современный уровень используемых объемов памяти — в мега-, или даже гигабайтах.
Ширина модуля — это разрядность его интерфейса шины данных, которая соответствует разрядности шины данных контроллера памяти и для всех современных типов контроллеров памяти SDRAM (SDR, DDR и DDR2) составляет 64 бита. Таким образом, все современные модули характеризуются шириной интерфейса шины данных «x64». Каким же образом достигается соответствие между 64-битная шириной шины данных контроллера памяти (64-битным интерфейсом модуля памяти), когда типичная ширина внешней шины данных микросхем памяти обычно составляет всего 4, 8 или 16 бит? Ответ очень прост — интерфейс шины данных модуля составляется простым последовательным «слиянием» внешних шин данных индивидуальных микросхем модуля памяти. Такое «заполнение» шины данных контроллера памяти принято называть составлением физического банка памяти. Таким образом, для составления одного физического банка 64-разрядного модуля памяти SDRAM необходимо и достаточно наличие 16 микросхем x4, 8 микросхем x8 (это наиболее часто встречаемый вариант) или 4 микросхем x16.
Оставшийся параметр — глубина модуля, являющийся характеристикой емкости (вместимости) модуля памяти, выраженной в количестве «слов» определенной ширины, вычисляется, как нетрудно догадаться, простым делением полного объема модуля (выраженного в битах) на его ширину (разрядность внешней шины данных, также выраженную в битах). Так, типичный 512-МБ модуль памяти SDR/DDR/DDR2 SDRAM имеет глубину, равную 512МБайт * 8 (бит/байт) / 64 бита = 64М. Соответственно, произведение ширины на глубину дает полную емкость модуля и определяет его организацию, или геометрию, которая в данном примере записывается в виде «64Мx64».
Возвращаясь к физическим банкам модуля памяти, заметим, что при использовании достаточно «широких» микросхем x8 или x16 ничего не мешает поместить и большее их количество, соответствующее не одному, а двум физическим банкам — 16 микросхем x8 или 8 микросхем x16. Так различают однобанковые (или «одноранковые», single-rank) и двухбанковые («двухранковые», dual-rank) модули. Двухбанковые модули памяти наиболее часто представлены конфигурацией «16 микросхем x8», при этом один из физических банков (первые 8 микросхем) расположен с лицевой стороны модуля, а второй из них (оставшиеся 8 микросхем) — с тыльной. Наличие более одного физического банка в модуле памяти нельзя считать определенным преимуществом, т.к. может потребовать увеличения задержек командного интерфейса, которые рассмотрены в соответствующем разделе.
Модули памяти: Микросхема SPD
Еще до появления первого типа синхронной динамической оперативной памяти SDR SDRAM стандартом JEDEC предусматривается, что на каждом модуле памяти должна присутствовать небольшая специализированная микросхема ПЗУ, именуемая микросхемой «последовательного обнаружения присутствия» (Serial Presence Detect, SPD). Эта микросхема содержит основную информацию о типе и конфигурации модуля, временных задержках (таймингах, см. следующий раздел), которых необходимо придерживаться при выполнении той или иной операции на уровне микросхем памяти, а также прочую информацию, включающую в себя код производителя модуля, его серийный номер, дату изготовления и т.п. Последняя ревизия стандарта SPD модулей памяти DDR2 также включает в себя данные о температурном режиме функционирования модулей, которая может использоваться, например, для поддержания оптимального температурного режима посредством управления синхронизацией (регулированием скважности импульсов синхросигнала) памяти (так называемый «троттлинг памяти», DRAM Throttle). Более подробную информацию о микросхеме SPD и о том, как выглядит ее содержимое можно получить в нашей статье «SPD — схема последовательного детектирования», а также в серии наших исследований модулей оперативной памяти.
Тайминги памяти
Немаловажной категорией характеристик микросхем/модулей памяти являются «тайминги памяти» — понятие, наверняка так или иначе знакомое каждому пользователю ПК. Понятие «таймингов» тесно связано с задержками, возникающими при любых операциях с содержимым ячеек памяти в связи со вполне конечной скоростью функционирования устройств SDRAM, как и любых других интегральных схем. Задержки, возникающие при доступе в память, также принято называть «латентностью» памяти (этот термин не совсем корректен, и пришел в обиход с буквальным переводом термина latency, означающего «задержка»).
В этом разделе мы рассмотрим, где именно возникают задержки при операциях с данными — содержимым микросхем памяти, и как они связаны с важнейшими параметрами таймингов памяти. Поскольку в настоящем руководстве мы рассматриваем модули памяти класса SDRAM (SDR, DDR и DDR2), ниже мы рассмотрим конкретную схему доступа к данным, содержащимся в ячейках памяти микросхемы SDRAM. В этом разделе мы также рассмотрим несколько иную категорию таймингов, связанных не с доступом к данным, но с выбором номера физического банка для маршрутизации команд по командному интерфейсу модулей памяти класса SDRAM — так называемые «задержки командного интерфейса».
Схема доступа к данным микросхемы SDRAM
1. Активизация строки
Перед осуществлением любой операции с данными, содержащимися в определенном банке микросхемы SDRAM (чтения — команда READ, или записи — команда WRITE), необходимо «активизировать» соответствующую строку в соответствующем банке. С этой целью, на микросхему подается команда активизации (ACTIVATE) вместе с номером банка (линии BA0-BA1 для 4-банковой микросхемы) и адресом строки (адресные линии A0-A12, реальное количество которых зависит от количества строк в банке, в рассматриваемом примере 512-Мбит микросхемы памяти SDRAM их число составляет 213 = 8192).
Активизированная строка остается открытой (доступной) для последующих операций доступа до поступления команды подзарядки банка (PRECHARGE), по сути, закрывающей данную строку. Минимальный период «активности» строки — от момента ее активации до момента поступления команды подзарядки, определяется минимальным временем активности строки (Row Active Time, tRAS).
Повторная активизация какой-либо другой строки того же банка не может быть осуществлена до тех пор, пока предыдущая строка этого банка остается открытой (т.к. усилитель уровня, содержащий буфер данных размером в одну строку банка и описанный в разделе «Микросхемы SDRAM: Физическая организация и принцип работы», является общим для всех строк данного банка микросхемы SDRAM). Таким образом, минимальный промежуток времени между активизацией двух различных строк одного и того же банка определяется минимальным временем цикла строки (Row Cycle Time, tRC).
В то же время, после активизации определенной строки определенного банка микросхеме SDRAM ничего не мешает активизировать какую-либо другую строку другого банка (в этом и заключается рассмотренное выше преимущество «многобанковой» структуры микросхем SDRAM) на следующем такте шины памяти. Тем не менее, в реальных условиях производителями устройств SDRAM обычно здесь также умышленно вводится дополнительная задержка, именуемая «задержкой от активации строки до активации строки» (Row-to-Row Delay, tRRD). Причины введения этой задержки не связаны с функционированием микросхем памяти как таковых и являются чисто электрическими — операция активизации строки потребляет весьма значительное количество электрического тока, в связи с чем частое их осуществление может приводить к нежелательным избыточным нагрузкам устройства по току.
2. Чтение/запись данных
Следующий временной параметр функционирования устройств памяти возникает в связи с тем, что активизация строки памяти сама по себе требует определенного времени. В связи с этим, последующие (после ACTIVATE) команды чтения (READ) или записи (WRITE) данных не могут быть поданы на следующем такте шины памяти, а лишь спустя определенный временной интервал, называемый «задержкой между подачей адреса строки и столбца» (RAS#-to-CAS# Delay, tRCD).
Итак, после прошествия интервала времени, равного tRCD, при чтении данных в микросхему памяти подается команда READ вместе с номером банка (предварительно активизированного командой ACTIVATE) и адресом столбца. Устройства памяти типа SDRAM ориентированы на чтение и запись данных в пакетном (Burst) режиме. Это означает, что подача всего одной команды READ (WRITE) приведет к считыванию из ячеек (записыванию в ячейки) не одного, а сразу нескольких подряд расположенных элементов, или «слов» данных (разрядность каждого из которых равна ширине внешней шины данных микросхемы — например, 8 бит). Количество элементов данных, считываемых одной командой READ или записываемых одной командой WRITE, называется «длиной пакета» (Burst Length) и обычно составляет 2, 4 или 8 элементов (за исключением экзотического случая передачи целой строки (страницы) — «Full-Page Burst», когда необходимо дополнительно использовать специальную команду BURST TERMINATE для прерывания сверхдлинной пакетной передачи данных). Заметим, что для микросхем памяти типа DDR и DDR2 параметр Burst Length не может принимать значение меньше 2 и 4 элементов, соответственно — причину этого мы рассмотрим ниже, в связи с обсуждением различий в реализации устройств памяти SDR/DDR/DDR2 SDRAM.
Возвращаясь к чтению данных, заметим, что существует две разновидности команды чтения. Первая из них является «обычным» чтением (READ), вторая называется «чтением с автоматической подзарядкой» (Read with Auto-Precharge, «RD+AP»). Последняя отличается тем, что после завершения пакетной передачи данных по шине данных микросхемы автоматически будет подана команда подзарядки строки (PRECHARGE), тогда как в первом случае выбранная строка микросхемы памяти останется «открытой» для осуществления дальнейших операций.
После подачи команды READ, первая порция данных оказывается доступной не сразу, а с задержкой в несколько тактов шины памяти, в течение которой данные, считанные из усилителя уровня, синхронизируются и передаются на внешние выводы микросхемы. Задержка между подачей команды чтения и фактическим «появлением» данных на шине считается наиболее важной и именуется пресловутой «задержкой сигнала CAS#» (CAS# Latency, tCL). Последующие порции данных (в соответствии с длиной передаваемого пакета) оказываются доступными без каких-либо дополнительных задержек, на каждом последующем такте шины памяти (по 1 элементу за такт для устройств SDR, по 2 элемента в случае устройств DDR/DDR2).
Операции записи данных осуществляются аналогичным образом. Точно также существуют две разновидности команд записи — простая запись данных (WRITE) и запись с последующей автоматической подзарядкой строки (Write with Auto-Precharge, «WR+AP»). Точно также при подаче команды WRITE/WR+AP на микросхему памяти подаются номер банка и адрес столбца. Наконец, точно также запись данных осуществляется «пакетным» образом. Отличия операции записи от операции чтения следующие. Во-первых, первую порцию данных, подлежащих записи, необходимо подать по шине данных одновременно с подачей по адресной шине команды WRITE/WR+AP, номера банка и адреса столбца, а последующие порции, количество которых определяется длиной пакета — на каждом последующем такте шины памяти. Во-вторых, вместо «задержки сигнала CAS#» (tCL) важной здесь является иная характеристика, именуемая «периодом восстановления после записи» (Write Recovery Time, tWR). Эта величина определяет минимальный промежуток времени между приемом последней порции данных, подлежащих записи, и готовности строки памяти к ее закрытию с помощью команды PRECHARGE. Если вместо закрытия строки требуется последующее считывание данных из той же самой открытой строки, то приобретает важность другая задержка, именуемая «задержкой между операциями записи и чтения» (Write-to-Read Delay, tWTR).
3. Подзарядка строки
Цикл чтения/записи данных в строки памяти, который в общем случае можно обозначить «циклом доступа к строке памяти», завершается закрытием открытой строки банка с помощью команды подзарядки строки — PRECHARGE (которая, как мы уже отмечали выше, может быть «автоматической», т.е. являться составной частью команд «RD+AP» или «WR+AP»). Последующий доступ к этому банку микросхемы становится возможным не сразу, а по прошествию интервала времени, называемого «временем подзарядки строки» (Row Precharge Time, tRP). За этот период времени осуществляется собственно операция «подзарядки», т.е. возвращения элементов данных, соответствующих всем столбцам данной строки с усилителя уровня обратно в ячейки строки памяти.
Соотношения между таймингами
В заключение этой части, посвященной задержкам при доступе к данным, рассмотрим основные соотношения между важнейшими параметрами таймингов на примере более простых операций чтения данных. Как мы рассмотрели выше, в самом простейшем и самом общем случае — для пакетного считывания заданного количества данных (2, 4 или 8 элементов) необходимо осуществить следующие операции:
1) активизировать строку в банке памяти с помощью команды ACTIVATE;
2) подать команду чтения данных READ;
3) считать данные, поступающие на внешнюю шину данных микросхемы;
4) закрыть строку с помощью команды подзарядки строки PRECHARGE (как вариант, это делается автоматически, если на втором шаге использовать команду «RD+AP»).
Временной промежуток между первой и второй операцией составляет «задержку между RAS# и CAS#» (tRCD), между второй и третьей — «задержку CAS#» (tCL). Промежуток времени между третьей и четвертой операциями зависит от длины передаваемого пакета. Строго говоря, в тактах шины памяти он равен длине передаваемого пакета (2, 4 или 8), поделенного на количество элементов данных, передаваемых по внешней шине за один ее такт — 1 для устройств типа SDR, 2 для устройств типа DDR. Условно назовем эту величину «tBL».
Важно заметить, что микросхемы SDRAM позволяют осуществлять третью и четвертую операции в некотором смысле «параллельно». Чтобы быть точным — команду подзарядки строки PRECHARGE можно подавать за некоторое количество тактов x до наступления того момента, на котором происходит выдача последнего элемента данных запрашиваемого пакета, не опасаясь при этом возникновения ситуации «обрыва» передаваемого пакета (последняя возникнет, если команду PRECHARGE подать после команды READ с временным промежутком, меньшим x). Не вдаваясь в подробности, отметим, что этот промежуток времени составляет величину, равную величине задержки сигнала CAS# за вычетом единицы (x = tCL — 1).
Наконец, промежуток времени между четвертой операцией и последующим повтором первой операции цикла составляет «время подзарядки строки» (tRP).
В то же время, минимальному времени активности строки (от подачи команды ACTIVATE до подачи команды PRECHARGE, tRAS), по его определению, как раз отвечает промежуток времени между началом первой и началом четвертой операции. Отсюда вытекает первое важное соотношение между таймингами памяти:
tRAS, min = tRCD + tCL + (tBL — (tCL — 1)) — 1,
где tRCD — время выполнения первой операции, tCL — второй, (tBL — (tCL — 1)) — третьей, наконец, вычитание единицы производится вследствие того, что период tRAS не включает в себя такт, на котором осуществляется подача команды PRECHARGE. Сокращая это выражение, получаем:
tRAS, min = tRCD + tBL.
Достаточно поразительный вывод, вытекающий из детального рассмотрения схемы доступа к данным, содержащимся в памяти типа SDRAM, заключается в том, что минимальное значение tRAS не зависит(!) от величины задержки CAS#, tCL. Зависимость первого от последнего — достаточно распространенное заблуждение, довольно часто встречающееся в различных руководствах по оперативной памяти.
В качестве примера первого соотношения, рассмотрим типичную высокоскоростную память типа DDR с величинами задержек (tCL-tRCD-tRP) 2-2-2. При минимальной длине пакета BL = 2 (минимально возможной для DDR) необходимо затратить не менее 1 такта шины памяти для передачи пакета данных. Таким образом, в этом случае минимальное значение tRAS оказывается равным 3 (столь малое значение tRAS не позволяет выставить подавляющее большинство контроллеров памяти). Передача более длинных пакетов, состоящих из 4 элементов (BL = 4, tBL = 2), увеличивает это значение до 4 тактов, наконец, для передачи максимального по длине 8-элементного пакета (BL = 8, tBL = 4) требуемое минимальное значение tRAS составляет 6 тактов. Отсюда следует, что, поскольку большинство контроллеров памяти не позволяют указать значение tRAS < 5, разумно настроить подсистему памяти таким образом, чтобы длина передаваемого пакета была максимальной (BL = 8, в том случае, если этот параметр присутствует в настройках подсистемы памяти в BIOS материнской платы), а величина tRAS принимала значение, равное 6. Альтернативный вариант — BL = 4, tRAS = 5.
Второе важное соотношение между таймингами вытекает из того факта, что полный цикл пакетного чтения данных — от 1-й стадии до ее повторения — именуется собственно «минимальным временем цикла строки», tRC. Поскольку первые три стадии, как мы показали выше, не могут занимать время, меньшее tRAS, а последняя занимает время, строго равное tRP, получаем:
tRC = tRAS + tRP.
Заметим, что некоторые контроллеры памяти (например, интегрированный контроллер памяти процессоров AMD64) позволяют независимо устанавливать значения таймингов tRAS и tRC, что в принципе может привести к несоблюдению указанного выше равенства. Тем не менее, особого смысла это неравенство не имеет — оно лишь будет означать, что параметры tRAS, либо tRC будут автоматически «подстроены» (в сторону большего значения) для соблюдения рассмотренного равенства.
Схемы таймингов
Напоследок отметим, что четыре важнейших параметра таймингов памяти, расположенных в такой последовательности: tCL-tRCD-tRP-tRAS, принято называть «схемой таймингов». Такие схемы (например, 2-2-2-5 или 2.5-3-3-7 для памяти типа DDR; 3-3-3-9, 4-4-4-12 и 5-5-5-15 для памяти типа DDR2) достаточно часто можно встретить в спецификациях на модули оперативной памяти.
Строго говоря, такая последовательность не соответствует фактической последовательности возникновения задержек при доступе в микросхему памяти (так, tRCD располагается перед tCL, а tRAS — «где-то посередине»), поэтому на самом деле она отражает основные тайминги памяти, расположенные в порядке их значимости. Действительно, наиболее значимой является величина задержки CAS# (tCL), проявляющая себя при каждой операции чтения данных, тогда как параметры tRCD и tRP актуальны лишь при операциях на уровне строки памяти в целом (ее открытия и закрытия, соответственно).
Задержки командного интерфейса
Особой категорией таймингов, не связанных с доступом к данным, находящимся в ячейках микросхем SDRAM, можно считать так называемые «задержки командного интерфейса», или обратную им характеристику — «скорость подачи команд» (command rate). Эти задержки связаны с функционирования подсистемы памяти на уровне не индивидуальных микросхем, а составляемых ими физических банков. При инициализации подсистемы памяти каждому сигналу выбора кристалла (chip select), ассоциированному с определенным физическим банком памяти, в регистрах чипсета присваивается определенный номер (нумерация осуществляется, как правило, по емкости физических банков — например, по убывающей), уникальным образом идентифицирующий данный физический банк при каждом последующем запросе (поскольку все физические банки разделяют одни и те же, общие шины команд/адресов и данных). Чем больше физических банков памяти присутствует на общей шине памяти, тем больше электрическая емкостная нагрузка на нее, с одной стороны, и тем больше задержка распространения сигнала (как прямое следствие протяженности пути сигнала) и задержка кодирования/декодирования и работы логики адресации и управления, с другой.
Так возникают задержки на уровне командного интерфейса, которые на сегодняшний день наиболее известны для платформ, основанных на процессорах семейства AMD Athlon 64 с интегрированным контроллером памяти, поддерживающим память типа DDR SDRAM. Разумеется, это не означает, что задержки командного интерфейса присущи лишь этому типу платформ — просто для этого типа платформ, как правило, в настройках подсистемы памяти в BIOS есть настройка параметра «Command Rate: 1T/2T», тогда как в других современных платформах (например, семейства Intel Pentium 4 с чипсетами Intel 915, 925, 945, 955 и 975 серий) настройки задержек командного интерфейса отсутствуют в явном виде и, по всей видимости, регулируются автоматически. Возвращаясь к платформам AMD Athlon 64, включение режима «2T» приводит к тому, что все команды подаются (наряду с соответствующими адресами) на протяжении не одного, а двух тактов шины памяти, что определенно сказывается на производительности, но может быть оправдано с точки зрения стабильности функционирования подсистемы памяти. Более подробно этот вопрос мы рассмотрим в будущем (во второй, «практической» части настоящего руководства, посвященной выбору модулей памяти класса SDRAM).
DDR/DDR2 SDRAM: Отличия от SDR SDRAM
Выше мы рассмотрели организацию и принципы функционирования синхронных устройств памяти с одинарной скоростью передачи данных SDR SDRAM. В настоящем разделе мы рассмотрим, какие основные отличия привносят устройства с удвоенной скоростью передачи данных — DDR и DDR2 SDRAM.
Начнем с рассмотрения микросхем DDR SDRAM. По большей части они оказываются похожими на микросхемы SDR SDRAM — так, оба типа микросхем, как правило, имеют одинаковую логическую организацию (при одинаковой емкости), включая 4-банковую организацию массива памяти, и одинаковый командно-адресный интерфейс. Фундаментальные различия между SDR и DDR лежат в организации логического слоя интерфейса данных. По интерфейсу данных памяти типа SDR SDRAM данные передаются только по положительному перепаду («фронту») синхросигнала. При этом внутренняя частота функционирования микросхем SDRAM совпадает с частотой внешней шины данных, а ширина внутренней шины данных SDR SDRAM (от непосредственно ячеек до буферов ввода-вывода) совпадает с шириной внешней шины данных. В то же время, по интерфейсу данных памяти типа DDR (а также DDR2) данные передаются дважды за один такт шины данных — как по положительному перепаду синхросигнала («фронту»), так и по отрицательному («срезу»).
Возникает вопрос — как можно организовать удвоенную скорость передачи данных по отношению к частоте шины памяти? Напрашиваются два решения — можно либо увеличить в 2 раза внутреннюю частоту функционирования микросхем памяти (по сравнению с частотой внешней шины), либо увеличить в 2 раза внутреннюю ширину шины данных (по сравнению с шириной внешней шины). Достаточно наивно было бы полагать, что в реализации стандарта DDR было применено первое решение, но и ошибиться в эту сторону довольно легко, учитывая «чисто маркетинговый» подход к маркировке модулей памяти типа DDR, якобы функционирующих на удвоенной частоте (так, модули памяти DDR с реальной частотой шины 200 МГц именуются «DDR-400»). Тем не менее, гораздо более простым и эффективным — исходя как из технологических, так и экономических соображений — является второе решение, которое и применяется в устройствах типа DDR SDRAM. Такая архитектура, применяемая в DDR SDRAM, называется архитектурой «2n-предвыборки» (2n-prefetch). В этой архитектуре доступ к данным осуществляется «попарно» — каждая одиночная команда чтения данных приводит к отправке по внешней шине данных двух элементов (разрядность которых, как и в SDR SDRAM, равна разрядности внешней шины данных). Аналогично, каждая команда записи данных ожидает поступления двух элементов по внешней шине данных. Именно это обстоятельство объясняет, почему величина «длины пакета» (Burst Length, BL) при передаче данных в устройствах DDR SDRAM не может быть меньше 2.
Устройства типа DDR2 SDRAM являются логическим продолжением развития архитектуры «2n-prefetch», применяемой в устройствах DDR SDRAM. Вполне естественно ожидать, что архитектура устройств DDR2 SDRAM именуется «4n-prefetch» и подразумевает, что ширина внутренней шины данных оказывается уже не в два, а в четыре раза больше по сравнению с шириной внешней шины данных. Однако речь здесь идет не о дальнейшем увеличении количества единиц данных, передаваемых за такт внешней шины данных — иначе такие устройства уже не именовались бы устройствами «Double Data Rate 2-го поколения». Вместо этого, дальнейшее «уширение» внутренней шины данных позволяет снизить внутреннюю частоту функционирования микросхем DDR2 SDRAM в два раза по сравнению с частотой функционирования микросхем DDR SDRAM, обладающих равной теоретической пропускной способностью. С одной стороны, снижение внутренней частоты функционирования микросхем, наряду со снижением номинального питающего напряжения с 2.5 до 1.8 V (вследствие применения нового 90-нм технологического процесса), позволяет ощутимо снизить мощность, потребляемую устройствами памяти. С другой стороны, архитектура 4n-prefetch микросхем DDR2 позволяет достичь вдвое большую частоту внешней шины данных по сравнению с частотой внешней шины данных микросхем DDR — при равной внутренней частоте функционирования самих микросхем. Именно это и наблюдается в настоящее время — модули памяти стандартной скоростной категории DDR2-800 (частота шины данных 400 МГц) на сегодняшний день достаточно распространены на рынке памяти, тогда как последний официальный стандарт DDR ограничен скоростной категорией DDR-400 (частота шины данных 200 МГц).
За более подробной информацией о реализации DDR2 и основных отличиях ее от DDR мы рекомендуем обратиться к нашей статье «DDR2 — грядущая замена DDR. Теоретические основы и первые результаты низкоуровневого тестирования». А сейчас, по аналогии с DDR, нам осталось лишь рассмотреть, в каком количестве осуществляется считывание/запись данных в микросхемах DDR2, и какое минимальное значение может принимать величина длины пакета данных. Итак, поскольку DDR2 — это «все та же DDR», мы по-прежнему имеем удвоенную скорость передачи данных за один такт внешней шины данных — иными словами, на каждом такте внешней шины данных мы ожидаем получить не менее двух элементов данных (как всегда, разрядностью, равной разрядности внешней шины данных) при чтении, и обязаны предоставить микросхеме не менее двух элементов данных при записи. В то же время, вспоминаем, что внутренняя частота функционирования микросхем DDR2 составляет половину от частоты ее внешнего интерфейса. Таким образом, на один «внутренний» такт микросхемы памяти приходится два «внешних» такта, на каждый из которых, в свою очередь, приходится считывание/запись двух элементов. Следовательно, на каждый «внутренний» такт микросхемы памяти приходится считывание/запись сразу четырех элементов данных (отсюда и название — 4n-prefetch), т.е. все операции внутри микросхемы памяти осуществляются на уровне «4-элементных» блоков данных. Отсюда получаем, что минимальная величина длины пакета (BL) должна равняться 4. Можно доказать, что, в общем случае, архитектуре «2nn-prefetch» всегда соответствует минимальная величина Burst Length, равная 2n (n = 1 соответствует DDR; n = 2 — DDR2; n = 3 — грядущей DDR3).